LLM Fine-Tuning for Custom AI Business Solutions

Businesses are in constant search for new ways to integrate artificial intelligence into their everyday operations to improve both customers' and employees' experiences. Unfortunately, they can't just take an out-of-the-box model and deploy it without adjustments and customization. This is where fine-tuning large language models (LLMs) comes in — a process that lets companies train AI to meet their unique needs and speak their language.
Take a telecom provider, for instance, that wants to offer top-notch technical support. They could use fine-tuned AI Chatbot that’s familiar with their devices, network issues, and even individual customer plans, making customer interactions feel faster and more personal. Or consider retail, for instance, where personalized service is key, an artificial intelligence trained on customer history can make tailored recommendations and help answer questions in a way that feels almost human.
At Flyaps, we have been at the forefront of AI innovation for over a decade, helping businesses in various sectors, from HR to retail, telecoms and logistics, implement tailored artificial intelligence solutions. Today, we would like to discuss how LLM fine-tuning works and how you can tailor your models to meet your particular needs. Let’s start by answering the question: what is LLM fine-tuning?
How LLM fine-tuning works
Large language model fine-tuning involves taking an already pre-trained model and giving it additional training to adapt it to a specific task or domain. This is done using a set of training examples, which are pairs of inputs and their corresponding desired outputs.
The model doesn’t just memorize the training examples but learns new patterns and structures. The goal is to teach it to generate appropriate responses to new, unseen inputs similar to those it was trained on, using task/domain-specific data.
For instance, if we are fine-tuning an LLM for the legal domain, the input could be a legal question related to family law or employment law, and the output would be the correct legal response or advice. Once fine-tuned, the model can handle new legal questions that it hasn't been exposed to.
As the model processes these pairs, it adjusts its internal settings and weights. This means it learns to prioritize information relevant to the specialized tasks it is being trained for.
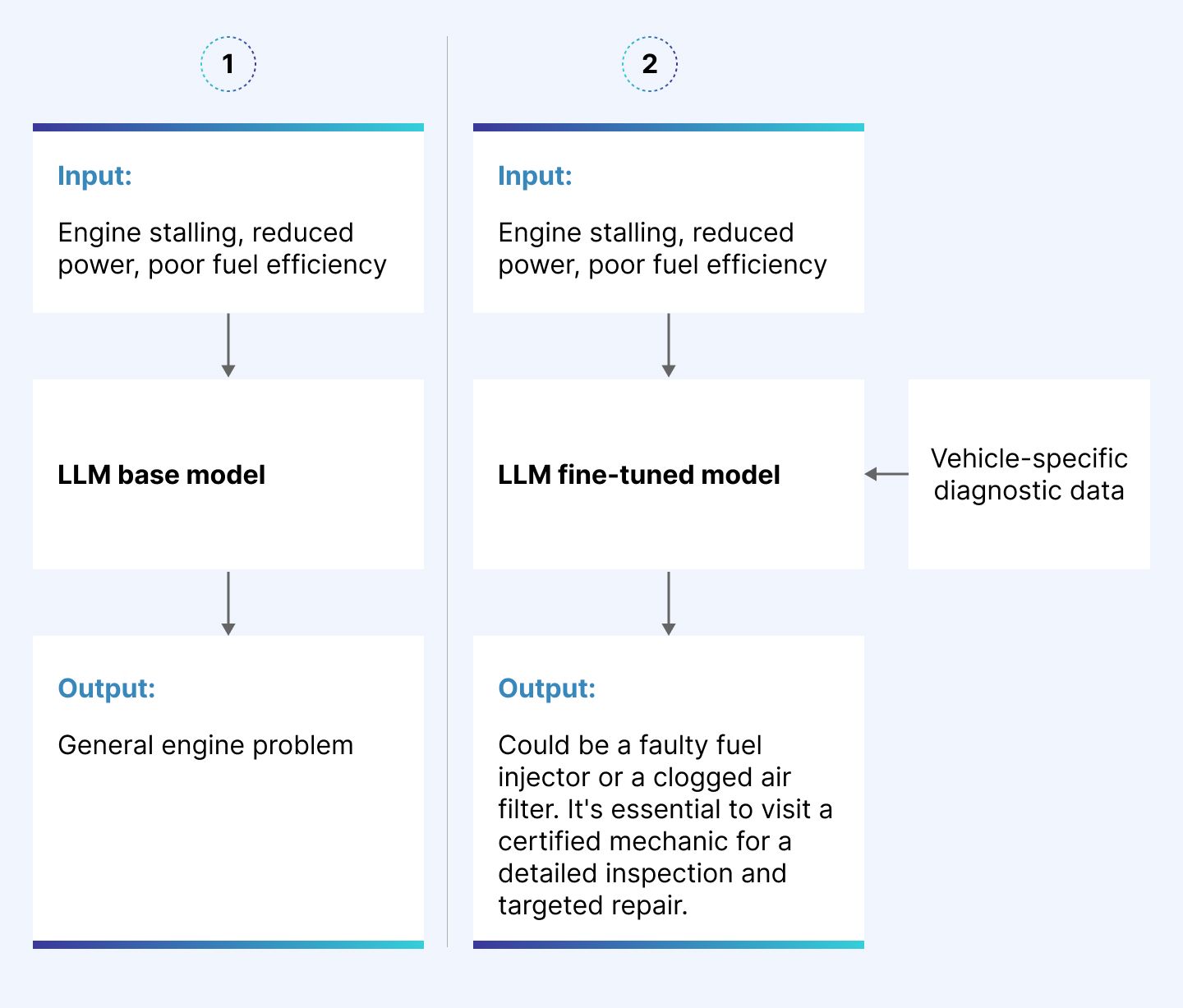
In which cases fine-tuning large language models is a great solution for your business?
Before we look at how LLMs can be fine-tuned, let's discuss who should consider this approach and why. If any of the following applies to your case, then LLM fine-tuning is your go-to.
For a broader understanding of how generative AI is being applied across industries, see our articles on "Generative AI use cases" and "Generative AI Models".
You have limited data
Let’s say you’re running a small e-commerce business and want to create a chatbot that can help customers find products fast. However, you only have a small dataset of customer interactions. Training a new model from scratch with limited data would be inefficient and likely result in poor performance. In this scenario, you should consider fine-tuning a pre-trained LLM with your own data. The model already understands language patterns, so it only needs a little extra information to serve your particular needs.
You’re tight on budget
Training an LLM from scratch requires a lot of time and resources. Fine-tuning process, on the other hand, is more cost-effective. You start with a model that has been trained on a vast knowledge base, so the only thing left to do is to adjust it with your specific data. This process takes fewer resources making it a budget-friendly option for businesses looking to implement AI solutions without breaking the bank.
You have task-specific needs
Suppose your business needs an AI system to handle a specific task, like translating technical documents or summarizing legal texts. For even more autonomous and complex task-handling, such as creating an AI Agent that can manage multi-step workflows, fine-tuning provides the necessary foundation for specialized understanding and action. A general LLM might not perform these tasks well enough because it hasn't been specifically trained for them. By fine-tuning the LLM with examples of the concrete task, you can tailor the model to perform exactly what you need, leading to better accuracy and efficiency.
You need domain-focused expertise
For example, you run a healthcare company and want the AI to analyze medical records and also assist in diagnosing diseases based on patient symptoms. A general LLM might not understand medical terminology and nuances like diagnostic criteria well enough for these tasks. By fine-tuning the LLM and exposing it to medical texts, pre-gathered patient records, and symptom databases, you can make it understand the specifics of medical language, diagnosis patterns, and treatment protocols. The outcome would be a fine-tuned model able to provide more accurate insights and recommendations, or in other words, a valuable tool for your business.
You want to improve data safety
There are strict laws regulating the use and handling of sensitive information, especially in industries like finance or healthcare. In addition, there are specific AI regulations that are constantly being updated and must be taken seriously. As a result, many organizations fear that the use of LLMs could jeopardize their data security and privacy, and even lead to legal problems. However, fine-tuning LLMs not only addresses these concerns but also enhances data protection.
In reality, the threat to data safety lies not in a model itself but in an environment where you fine-tune it. By “environment” we mean physical hardware, the software infrastructure, the data handling procedures, and the security measures. Creating a controlled and secure environment helps to ensure that sensitive information is never exposed or misused.
Suppose your organization is a financial institution and you want to use LLMs to create a chatbot that answers your customers' questions about their account information. By fine-tuning LLMs with your own secure and proprietary data, you can improve its ability to respond accurately to customer queries about account balances, transaction history or investment options.
During the fine-tuning process, the data used remains within your secure infrastructure and access to it is tightly controlled. This means your clients' personal and financial information is never at risk of being leaked or inappropriately accessed by unauthorized parties.
Now it’s time for us to discuss the actual methods of LLM fine-tuning. One important note, however. Before fine-tuning, you have to choose the right pre-trained LLM. There are many LLMs out there, with new ones being created almost every day, so if you haven’t picked one yet, we highly recommend reading our article on the How to Choose the Best LLM for Your Business.
AI can do more for your business—let’s find the best way to make it work for you. Check out our expertise and let’s discuss your next AI project.
See our AI servicesHow to fine-tune a large language model: top techniques to use
LLM fine-tuning methods can be split into two groups: supervised fine-tuning and reinforcement learning from human feedback (RLHF). Let’s start with the first one.
Supervised fine-tuning large language models
In supervised fine-tuning, the model is trained on a labeled dataset where each input is associated with a correct answer or label. It means that if you're fine-tuning a language model to, for example, classify emails as spam or not spam, the dataset would consist of emails (inputs) paired with labels like “spam” or “not spam”. Let’s look at what methods we have for supervised fine-tuning.
1. Basic hyperparameter tuning
Hyperparameters are the settings or configurations set before the training process begins. You may have come across a similar concept called model parameters. The difference is that model parameters are learned from the data during training.
The basic hyperparameters tuning technique involves manually adjusting hyperparameters (such as learning rate and number of training examples called “batch size”) to achieve the desired performance. The goal is to find the optimal set of hyperparameters that allow the model to learn effectively from the data.
Imagine you're training a sentiment analysis model to classify movie reviews as positive or negative. You start with a learning rate of 0.01 and a batch size of 32. After several training runs, you notice that the model overfits quickly, suggesting that the learning rate might be too high. By lowering the learning rate to 0.001 and increasing the batch size to 64, you manage to find a combination that reduces overfitting and improves validation accuracy.
2. Multi-task learning
In multi-task learning, the model is trained on multiple related tasks simultaneously. By learning to perform several tasks at once, the model can develop a more robust and generalized understanding. This technique works for cases when data for individual tasks is limited.
For example, you are building a natural language processing system for customer support. The system needs to deal with multiple related tasks such as intent classification, entity recognition, and sentiment analysis. By training a single model on datasets for all these tasks simultaneously, the model can leverage commonalities between tasks, such as recognizing that the sentiment of a sentence often correlates with certain intents, thereby improving its performance on each individual task.
3. Few-shot learning
Few-shot learning allows a model to adapt to a new task with minimal task-specific data. The model uses its vast pre-existing knowledge to learn effectively from just a few examples, making it ideal when labeled data is scarce.
For instance, you want the model to identify rare diseases from medical reports, but you only have a few labeled examples for each disease. Using a pre-trained language model that has been fine-tuned on a related, larger medical dataset, you apply few-shot learning. In this way, the model, armed with prior knowledge of medical terminology and concepts, can learn to find patterns that are similar to the patterns in the few labeled examples it's been trained on. As a result, the model effectively learns to identify rare diseases from the provided examples.
4. Task-specific LLM fine-tuning
This method is designed to fine-tune an LLM for a single, well-defined task. It allows the model to adapt its parameters to the nuances of the targeted task.
Suppose you are developing a chatbot to assist users with booking flights. After starting with a general language model, you fine-tune it on a dataset of flight booking dialogs, which includes user queries and booking confirmations. As a result, the model’s parameters are adjusted to better understand and respond to specific requests related to flights, such as recognizing flight numbers, dates, and destinations.

A data pipeline is an important element for the success of LLM projects. Want to know how to build one quickly and effectively?
Read our dedicated article “How to Build a Data Pipeline Fast (for AI and LLM Projects): Comparing Top Three Choices.”
5. Transfer learning
Transfer learning starts with a model pre-trained on a large, general dataset and can perform general language tasks (like translating simple text from English to French, for example). The model is then fine-tuned on specific task data (like creating poetry in the French Symbolist style), allowing it to adapt its pre-existing knowledge to the new task. This method is particularly useful when you have limited task-specific data, such as a small collection of French symbolic poetry samples.
Let’s say that for your project you have chosen BERT, an LLM trained on a vast amount of general text, and want to use it for developing a legal document classifier. By fine-tuning BERT on a smaller, labeled dataset of legal documents, the model can adapt its understanding of language to the specific vocabulary and phrasing typical in legal texts, leading to better performance than training it from scratch.

Working with LLMs and other generative AI models requires proper specialists. Which ones?
Read in our article “9 Generative AI Roles You Need for Your Business” to find out.
Now, let's look at another method to fine-tune an LLM – reinforcement learning from human feedback (RLHF).
Reinforcement learning from human feedback (RLHF)
RLHF involves training models through interactions with human feedback. This approach is perfect if you want to teach a language model to improve over time and produce more accurate and contextually appropriate responses when interacting with new users. Let’s consider five main LLM fine-tuning methods for RLHF.
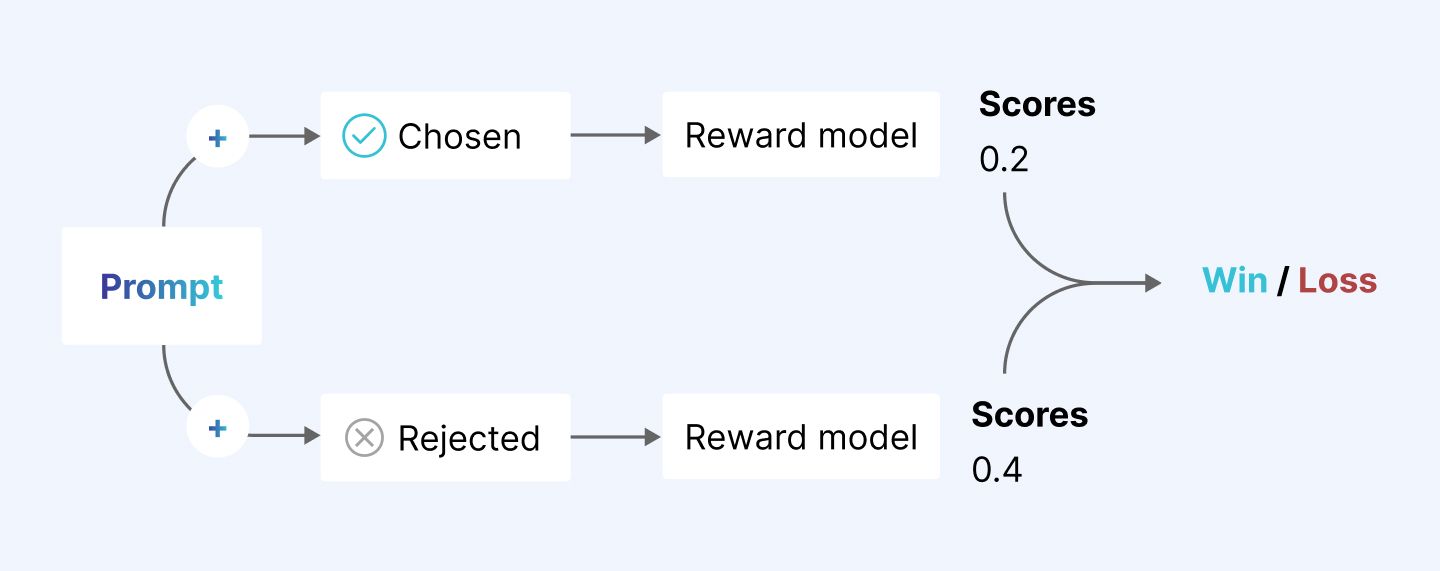
1. Reward modeling
With this method, the model generates several potential responses to user queries for human evaluators to rank them. The model learns to predict these ratings (or rewards), making its future outputs more like the higher-ranked ones.
2. Proximal policy optimization (PPO)
PPO is an iterative algorithm, meaning it repeats a series of steps to improve the model over time. At each iteration, the algorithm updates the model's policy, which comprises a set of rules or strategies for decision-making. The primary goal of these updates is to maximize expected rewards (rates) while at the same time ensuring that changes made to the policy are not too drastic. This precaution is crucial as significant changes could potentially disrupt the learning process. Therefore, PPO strikes a balance between maximizing rewards and maintaining stability in the learning process.
Let’s say you are looking to refine a gaming AI for it to play chess. Using PPO, the model iteratively updates its strategies to maximize its win rate. The algorithm ensures that each policy update makes gradual changes to the model's strategy, preventing major shifts that could destabilize learning and degrade performance, leading to a more robust and reliable chess-playing AI.
3. Comparative ranking
Just like in reward modeling, in comparative ranking human evaluators rank multiple outputs generated by the model. However, they differ in how this feedback is given and what it focuses on.
In comparative ranking, human evaluators compare and rank multiple responses generated by the model relative to each other. Instead of providing direct scores, evaluators focus on comparing the quality or appropriateness of different outputs.
For example, you're fine-tuning a customer support chatbot for a tech company. When a customer asks, “How do I reset my password?”, the chatbot generates several responses – A, B, C, D. Your task is to compare these responses and rank them based on clarity and helpfulness. That way, for instance, Response D is the best, followed by Response C, Response B, and finally Response A.
As an outcome, the chatbot learns from the rankings, not the score evaluators provide, thus understanding which answers are more relevant.
4. Preference learning
Preference learning is a method where a model learns what people prefer between two options. Instead of scoring each option individually, human evaluators compare two options and choose which one they like better.
This method works great when you are creating a recommendation system for a streaming service, for example. In the latter case, human evaluators are presented with pairs of recommended movie lists, shows or else and asked to choose their preferred one. The model learns from these preferences, adjusting its recommendation algorithm to better align with human choices, resulting in recommendations users are more likely to enjoy.
5. Parameter-efficient fine-tuning (PEFT)
Instead of updating the entire model, PEFT focuses on modifying only a small subset of the model's parameters. It targets the parameters that are most important for the task you want the model to perform better on. For example, if the model is being fine-tuned to understand medical texts better, PEFT will tweak the parameters related to language understanding in the medical context, significantly reducing the computational power and storage space required. This makes the fine-tuning process faster and more efficient.

Want to get the most out of your LLM-driven solution?
Use our practical tips for prompt engineering.
We’ve covered a lot of theory so far. Now it’s time we move to practice.
Example of step-by-step fine-tuning LLM process
For this part, picture this. You are working with Google's Gemini model for your project, a customer support chatbot system. However, you realize that the LLM struggles to accurately categorize technical support queries.
Can you improve its performance? Absolutely! You can fine-tune the LLM using a dataset containing technical support queries and their corresponding categories. Here are the steps to take.
Step 1. Select a pre-trained model and a dataset
In our case, we chose Gemini as it is famous for its capabilities in various NLP tasks. But it doesn’t mean you have to choose this particular model for your project. As we said earlier, the market is flooded with different LLMs, so feel free to choose the one that serves your business needs better.
Coming back to our example, just like all other models, Gemini is pre-trained to recognize certain categories or labels in text data. So if your dataset contains different categories, the model may not perform well unless it's adjusted.
Here's how to adjust the Gemini model:
Now, load the data. You can use a dataset containing technical support queries categorized into different topics like hardware issues, software issues, account issues, and such. Let’s assume we have such a dataset.
Step 2. Prepare the dataset
Preparation always starts with data cleansing. This process involves more than just removing duplicates and filling missing values. Depending on your dataset, you might also need to:
- Normalize text (lowercasing, removing punctuation).
- Remove stopwords (common words like “and” or “the”).
- Stem or lemmatize words (reducing words to their base or root form).
LLMs like Google's Gemini expect input data in the form of tokens. Raw text cannot be directly processed by these models. Therefore, you will have to tokenize the text data. Here’s how to do it.
To make the training process more efficient, create smaller subsets for training and evaluation.
Step 3. Initialize the model
Load the pre-trained Gemini model and specify the number of categories in your dataset. If you have more categories, you need to adjust the model (do it with the num_labels parameter).
Step 4. Define evaluation metrics
Before starting the training, define a function to evaluate the model’s performance. Simply put, set up a way to measure how well your model is doing on the task you want it to perform.
Accuracy is a common metric for classification tasks, but depending on your needs, you might also consider precision, recall, or F1 score. More about these metrics and model evaluation in general you will find in our article dedicated to the AI project life cycle.
Step 5. Fine-tune the model
Set up the training arguments, or in other words, specify how long the training should run, how big each batch of data should be, and how fast the model should learn. Then use the Trainer class to fine-tune the model. The Trainer automatically manages things like loading data, updating the model's parameters, and evaluating performance.
Basically, it’s like teaching a robot to identify different types of fruits from images. You need to decide how many examples of each fruit the robot will see at once, how many times it will look at all the examples (epochs), and how quickly it will adjust its understanding based on mistakes (learning rate).
Step 6. Evaluate the model
After the fine-tuning process, you need to check how well your model has learned the training data. Evaluating the model's performance on the test set means seeing how accurately it can make predictions on new, unseen data.

Thinking about using AI tools like GitHub Copilot for coding when fine-tuning LLMs?
Check out our article where we discuss whether it's a helpful tool “Is GitHub Copilot Worth It? Expert Opinions and Real-World Application.”
Fine-tuning LLM vs retrieval-augmented generation (RAG)
The fine-tuning process isn’t the only technique for improving pre-trained models. Businesses often choose between fine-tuning and retrieval-augmented generation. To understand when RAG might be a better option, let's delve into what RAG is and its advantages.
What is RAG and how does it work
RAG is a way to improve LLM’s outputs by connecting them to to specially selected and continually updated database. This way, models always have access to reliable and accurate information. For example, imagine a medical chatbot designed to provide health advice and answer patient queries.
Suppose someone asks, “What are the latest treatments for type 2 diabetes?” The RAG system searches its curated, dynamic medical database for the most recent and relevant articles, research papers, and medical guidelines on type 2 diabetes treatment. It retrieves top-ranked documents such as a recent study on a new medication, updated treatment guidelines from a reputable health organization, and a review article on advancements in diabetes management.
The “retrieval” aspect in the name of this approach is key as it is exactly the part that searches for relevant pieces of information before answering.
How does RAG differ from fine-tuning?
The final goal of both fine-tuning and RAG is the same - increase the value of an LLM for a business. However, the approach is different. Fine-tuning includes training models on a specific dataset so it can “understand” the context of that specific domain. On the other hand, RAG is a cheaper and more straightforward approach. RAG improves a model's responses by giving it access to an up-to-date database when needed. So there's no need for training with RAG, nor for retraining models over time to give more relevant answers.
When to use RAG instead of fine-tuning
For some business needs, RAG is a better choice than fine-tuning because it offers more security. With RAG, your proprietary data remains safely within your secure database environment, where you have tight control over access. Unlike fine-tuning, where your data becomes part of the model's training set and can be exposed more widely. RAG is also more cost-effective in terms of time and computing power.
The choice between RAG and fine-tuning depends on what you need and the resources you have. RAG may be the right choice because of its security and reliability. But if you have a specific domain that requires deep customization, fine-tuning will work better for you. Sometimes using both together can give you great results.
Final thoughts
From articles and YouTube videos, fine-tuning LLMs seems like a straightforward task. But in reality, it requires a deep understanding of LLMs’ complexity with all their layers and parameters that interact in intricate ways. Successfully implementing these advanced techniques often requires the expertise of a specialized provider of Generative AI development services to ensure optimal performance and alignment with business goals. Some fine-tuning tasks might only need minor tweaks, while others could require significant changes to the model.
Given these challenges, it's better to trust this process to a AI and ML team with extensive experience in fine-tuning LLMs and a deep understanding of your specific industry. At Flyaps, we have worked on projects for fields like telecom, HR and recruitment, logistics, retail, fintech and even urban planning. By constantly analyzing the technical solutions used by leaders in these domains, our AI and data engineers can bring you customized and innovative LLM applications that align with your business goals.
Don't want to navigate fine-tuning LLMs alone? Drop us a line to get tailored AI solutions that work for you.
Skip the endless hiring cycles. Scale your team fast with AI/ML specialists who delivered for Indeed, Orange, and Rakuten.
Scale your team



