Explaining Data Pipelines: What You’re Missing Out On If Not Building Them

You’ve probably seen the results of a data pipeline, even if you might not have realized that.
It might be the sales dashboard that updates each morning with fresh CRM numbers. Or the marketing report that pulls ad spend from Google, Facebook, and LinkedIn. Or the finance tracker that automatically updates with a .csv file of yesterday’s transactions.
In each case, there’s a process working behind the scenes: collecting data from different places, cleaning it up, and delivering it where it’s needed.
That’s a data pipeline process in a nutshell.

A data pipeline is a series of steps that moves data from point A to point B, usually to make it usable(a bit vague definition, we know, but we break the process down in the very next section). That could be as simple as uploading a .txt file into a database table. Or as complex as running live machine learning operations, such as making predictions on streaming data.
AI development platforms often rely on robust data pipelines like these to ensure models are trained and updated with accurate, timely information.
At Flyaps, we’ve been dealing with machine learning projects since 2016, from simple automated data flows to full-scale data platforms. One of our projects includes Airbyte, an open-source tool for creating no-code pipelines, which reached unicorn status in just two years, raising $181M and earning a $1.5B valuation.
In this article, we break down why building data pipelines is a must for data-driven businesses.
Data pipeline is a fairly generic term. Let’s unpack it.
To better understand how a data pipeline actually moves data from point A to point B, let’s look at a more formal—and widely accepted—definition from Joe Reis and Matt Housley, authors of the bestselling Fundamentals of Data Engineering:
“A data pipeline is the combination of architecture, systems, and processes that move data through the stages of the data engineering lifecycle.”
The authors gave a loose definition on purpose because data pipelines look different from company to company. Some are as simple as sending data from a form into a spreadsheet. Others are as complex as handling billions of events per day and powering machine learning systems (*we’ll look at both examples later). Besides, data teams usually manage multiple pipelines at once, which often depend on each other.
The point is: a data pipeline is whatever combination of tools and steps gets your data from A to B, in a way that works for you. But let’s go through the above definition further.
“Architecture, systems, and processes…” → What are those, exactly?
- Architecture = the blueprint. It defines how and where data flows. (We go over common architecture patterns, like ETL, ELT, and such later in the article.)
- Systems = the actual tools and platforms (think: databases, APIs, warehouses, cloud storage).
- Processes = the tasks that make the pipeline actually work:
- collecting data
- transforming and cleaning it
- validating it for quality
- monitoring it for issues like data drift (when the incoming data shifts in a way that might break your models or reports).
Together, they make sure your data doesn’t just sit there. It flows, gets cleaned up, and ends up in the right place. 👇
“Move data…” → From where to where, exactly, and why?
Data usually starts in a messy place, scattered across systems and tools, like CRMs, support platforms, mobile apps, ERP systems, IoT sensors, third-party APIs, and internal databases. It needs to move through a series of steps, like getting cleaned, organized, and checked, before it’s ready to be used, whether that’s in a dashboard, a data warehouse, or a machine learning model.
The pipeline is what connects all these steps, so the data gets from the raw source → useful information.
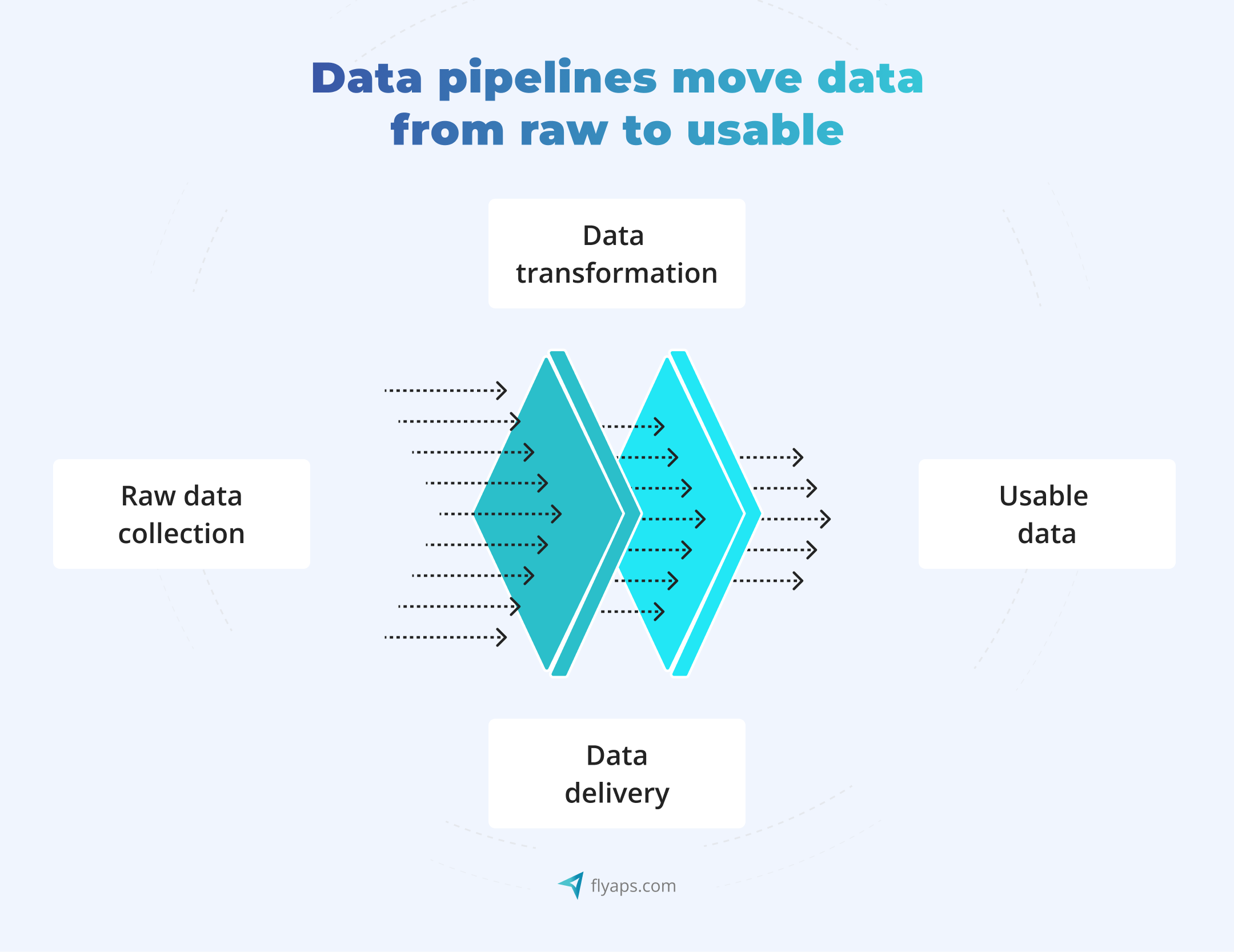
This kind of system becomes especially important in data-heavy environments, like real-time analytics platforms, AI-driven apps, or autonomous vehicles. 👇
Take Tesla, for example. In their 2019 patent, they describe a custom machine learning pipeline that powers their self-driving system. Their AI pipeline takes raw camera and sensor data from its vehicles, cleans it, feeds it into a neural network, and uses the results to control the car, all in real time. Without that pipeline, the AI wouldn’t have reliable data to make split-second decisions.
But how does that data actually turn from raw into usable? That leads us to the data engineering lifecycle.
“Stages of the data engineering lifecycle” → What are those?
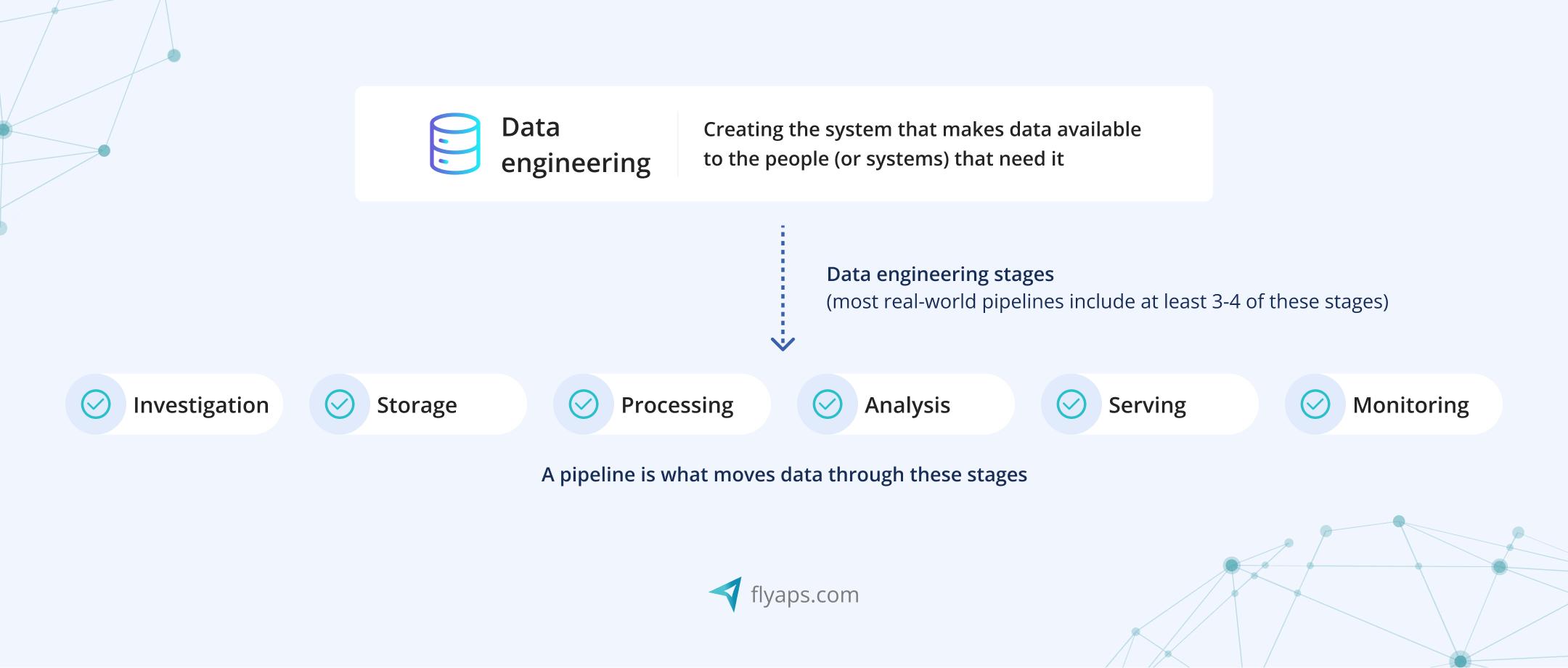
Data engineering means building the infrastructure that makes data available to people, tools, or other systems.
Most pipelines touch at least a few stages of the data engineering lifecycle. You might not need all of them in every pipeline, but here’s what a typical setup looks like:
- Data ingestion: Collecting data from different sources, like APIs, databases, spreadsheets, logs, and so on.
- Data storage: Storing that data somewhere safe (and scalable), like a data lake or warehouse.
- Data processing/transformation: Cleaning and combining it, fixing errors, reshaping formats, removing duplicates.
- Data modeling/analysis: Structuring it so analysts, dashboards, or ML models can use it.
- Data serving: Delivering it to wherever it needs to go — dashboards, reports, apps.
- Data monitoring: Making sure nothing breaks and the data is accurate and up to date.
So here’s what we mean when we talk about a “data pipeline”
A data pipeline is the system that connects all of these stages. It’s how raw, messy data gets collected, cleaned, and delivered to the tools or people who need it.
Does that mean you need the whole data engineering stack to build a pipeline?
Not at all. You can start with a focused data pipeline that addresses a specific business need without committing to the full data engineering ecosystem immediately. But you should recognize that this pipeline is part of a larger system, and designing it with that broader context in mind will pay off as your data needs evolve.
If you're thinking about how to align these pipelines with broader business goals and future AI use, check out our guide to AI Implementation strategies for practical insights.
Tip: Set up your pipeline in small, reusable steps instead of one big script. For example, separate ingestion, cleaning, and loading into distinct parts. This makes it easier to swap data sources, add new steps, or let other teams reuse pieces. Tools like Airflow, Dagster, or Prefect can help manage these steps independently, making your pipeline easier to scale and maintain as you grow.
Think of building a pipeline like opening one production line in a factory. You don’t need the full facility built out from day one. But if you know you’re growing fast, it makes sense to lay down the foundations properly so other lines can be added without tearing everything down.
Examples of simple and complex data pipelines
The complexity of a data pipeline depends on the size, structure, and data messiness, as well as what the business needs to do with it. Here's how pipelines can range from basic to sophisticated.
A simple pipeline to monitor app performance
Scenario: A SaaS company wants to monitor how their app performs, including load times, error rates, and unusual spikes in activity. They need a weekly system health report, but don’t want engineers digging through raw logs manually.
A simple data pipeline here would be:
→ Extract server logs from multiple application instances.
→ Load them into an Amazon S3 bucket throughout the day.→ Process & structure the logs into a readable format — filter out noise, extract key fields (timestamps, error codes, request paths).→ Load the cleaned data into an Amazon Redshift database to search through it later.
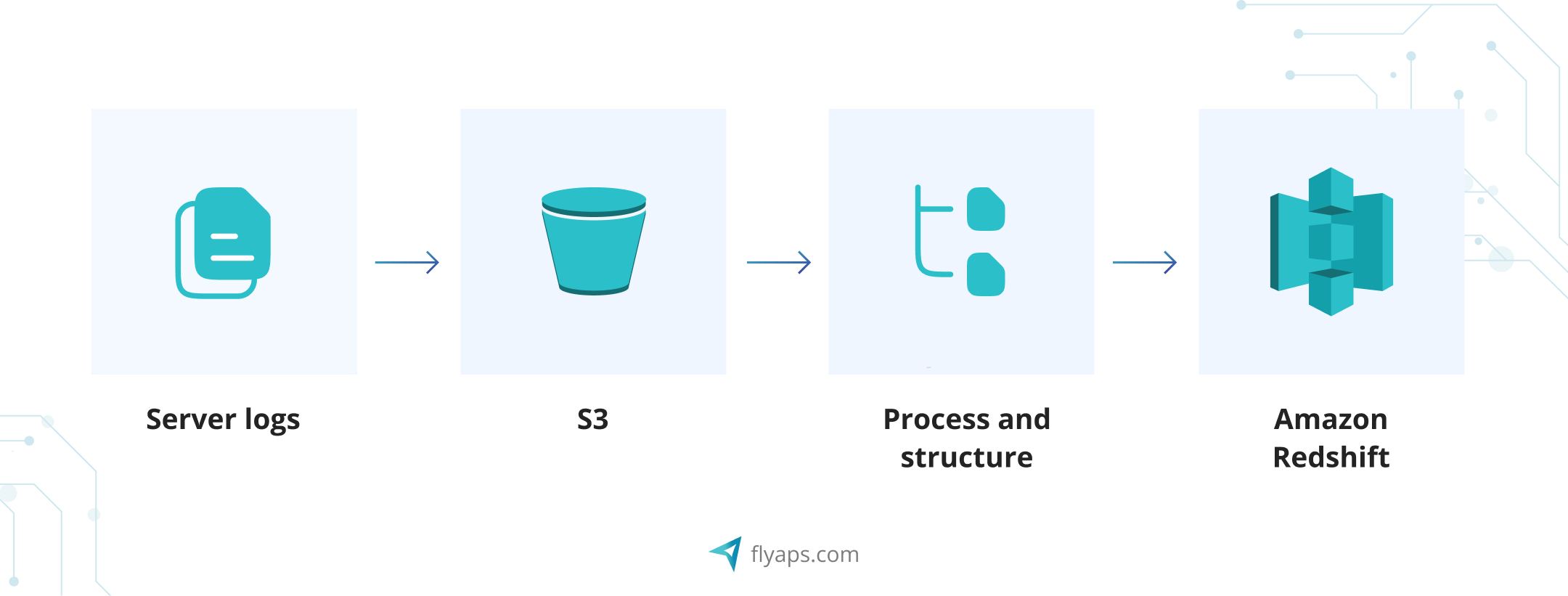
Once the data is in Redshift, the team can use BI tools like Looker or Tableau to visualize trends and spot issues.
A complex automated data pipeline to consolidate data
Scenario: A company needs to bring together data from multiple tools and teams to create a single, reliable source of truth.
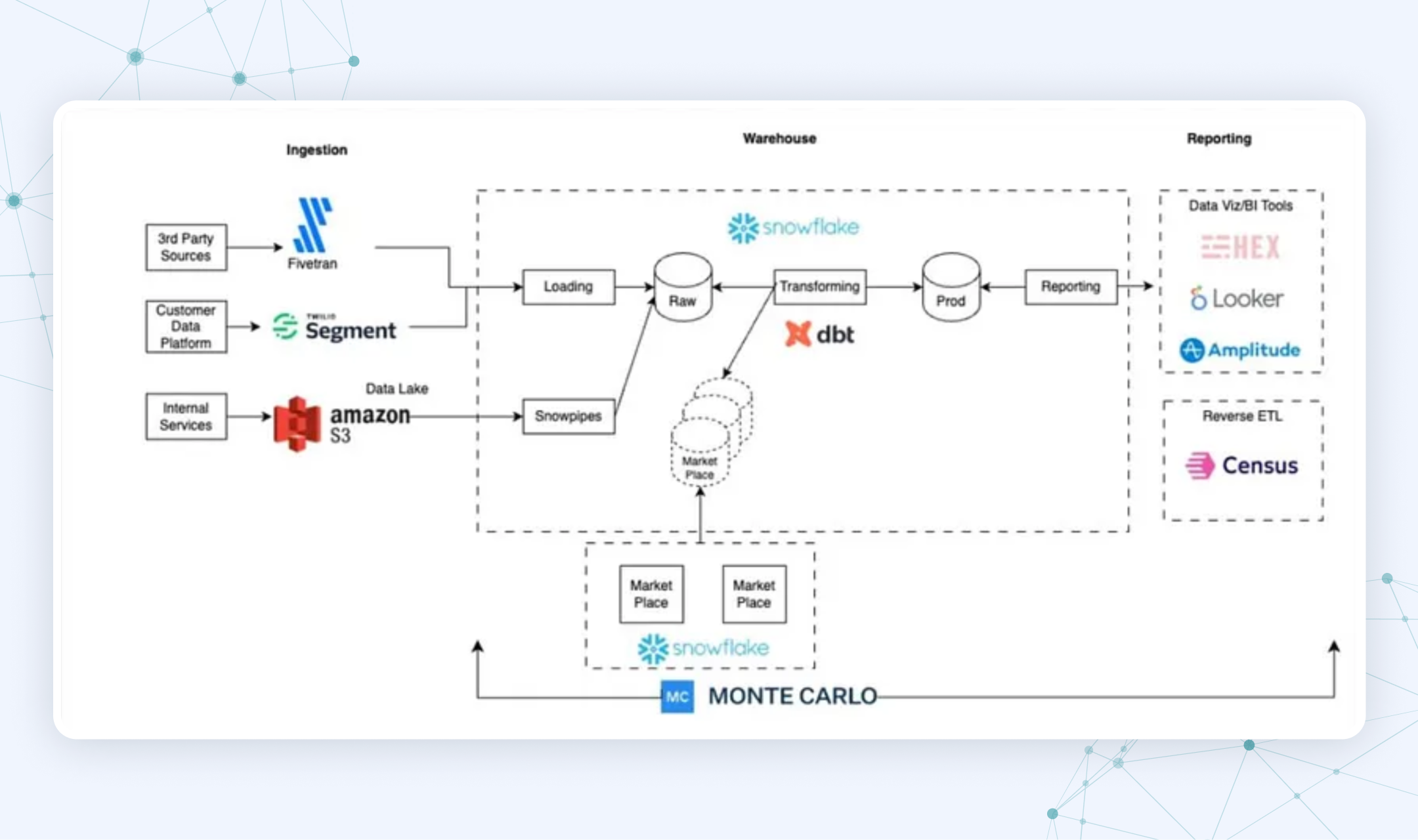
Here’s a real-life example: At Swimply, a platform where people can rent private pools, marketing, product, support, and operations all track their own metrics. Their goal was to centralize that data so the company could make fast, data-backed decisions, without stitching together spreadsheets by hand.
A complex data pipeline here would be:
→ Use Fivetran and Segment to automatically extract data from third-party apps, internal services, and customer interactions. → Store raw data in a Snowflake data warehouse. → Automate transformations with dbt — cleaning, organizing, and preparing the data for analysis. → Monitor pipeline health and data quality with Monte Carlo. → Feed the processed data into tools like Looker, Hex, and Amplitude for reporting, and use Census for reverse ETL to send insights back into operational tools.
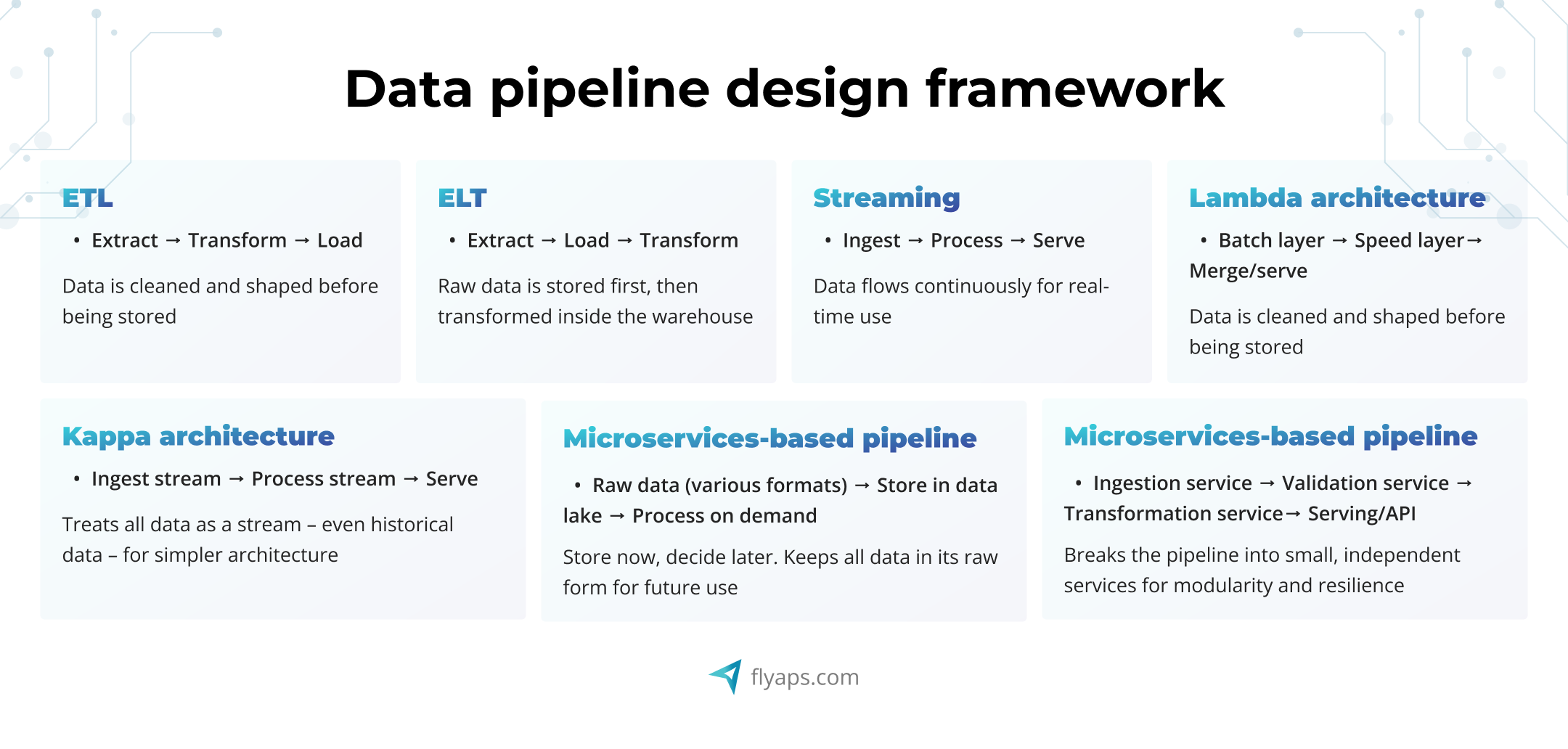
7 common frameworks to design a data pipeline
How you design your data pipeline depends on whether you need real-time insights, historical reporting, or both.
Before we get into the most popular pipeline frameworks, we need to first see the two main ways data is processed: batch and streaming.
Batch processing means collecting data over a period of time (like hourly, daily, or weekly), then processing it all at once in a “batch.” Streaming processing means handling data continuously as it arrives, usually in real time or close to it.
Here’s how two compare:
| Batch processing | Streaming processing | |
| Data handling | In chunks (for example, daily) | Continuously, as it arrives |
| Latency | Minutes to hours | Seconds or milliseconds |
| Typical use cases | Reporting, analytics, backups | Dashboards, fraud detection, alerts |
| Complexity | Easier to build and maintain | More complex and resource-intensive |
| Tools often used | Airflow, dbt, Snowflake | Kafka, Spark Streaming, Flink |
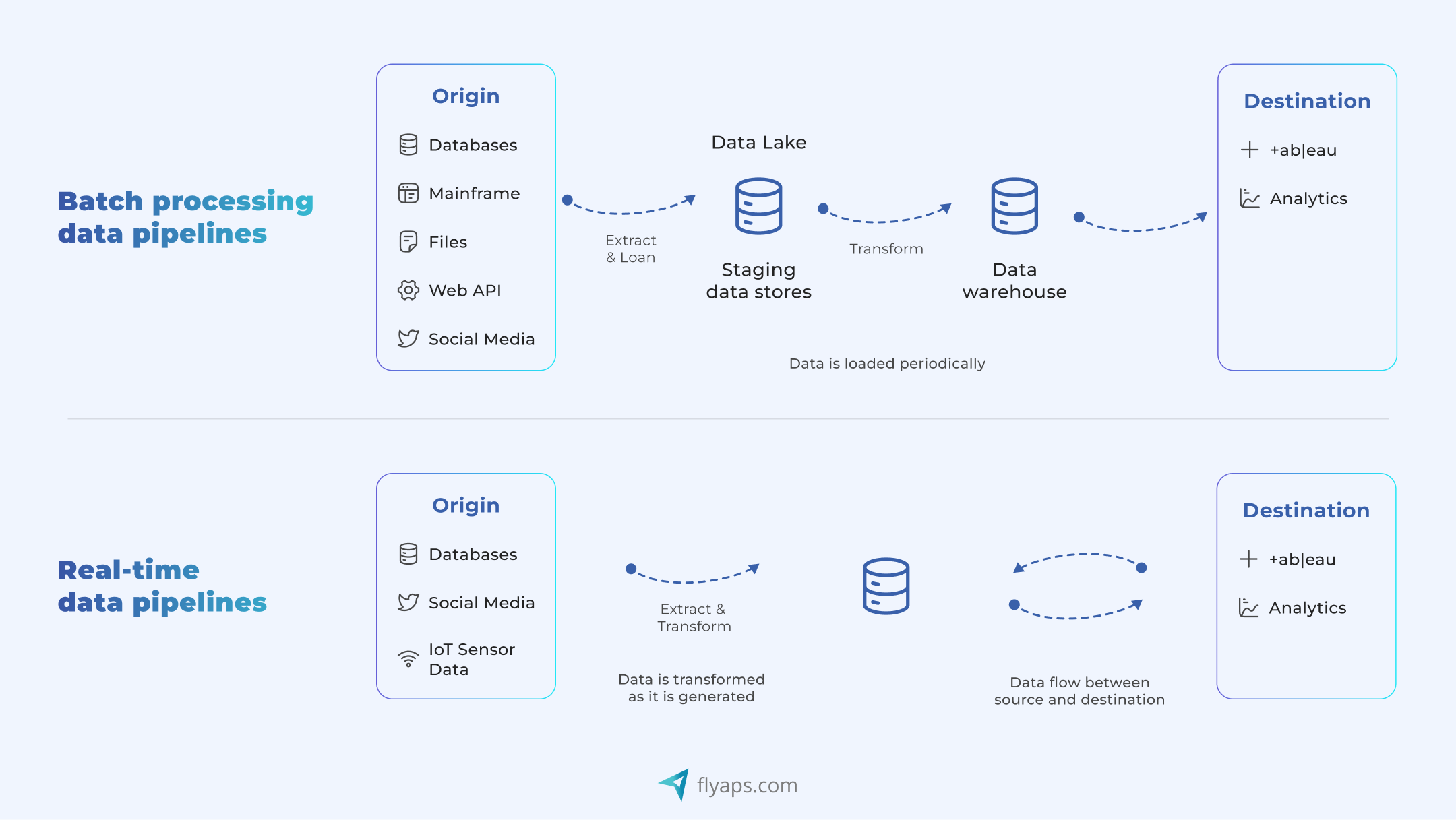
Most of the frameworks we’ll cover below are really just different ways of doing batch, streaming, or a mix of both. That said, here’s a breakdown of the most common pipeline architectures, when to use them, and what trade-offs to expect:
ETL (Extract, Transform, Load) pipeline
Pulls the data from its source, cleans and transforms it, then loads it into your destination system (like a warehouse).
Best for: Complex transformations, high data quality, structured data
Watch out for: It’s batch-based, so it can be slow and resource-intensive for large datasets.
ELT (Extract, Load, Transform) pipeline
Loads raw data into your warehouse first, then transforms it there using tools like dbt.
Best for: Scalability, flexibility with modern cloud data warehouses (for instance, Snowflake, BigQuery)
Watch out for: Less suited for very complex transformations.
Streaming pipelines
Data flows continuously through the pipeline — often using tools like Kafka or Spark Streaming — enabling real-time insights.
Best for: Live dashboards, event-driven systems (for example, fraud detection, IoT monitoring)
Watch out for: More complex to build and maintain, and can be resource-heavy.
Lambda architecture
Combines batch and streaming layers to handle both real-time and historical data. Often used in big data environments.
Best for: AI use cases that require both fast and accurate insights
Watch out for: Two layers = more complexity and maintenance overhead.
Kappa architecture
Simplifies Lambda by treating all data as a stream, historical or real-time.
Best for: Scalable real-time systems without the need for batch jobs
Watch out for: Reprocessing large streams or correcting past data can be tricky.
Data lake architecture
Lets you store all your raw data (structured, semi-structured, unstructured) in one place, like S3 or Azure Data Lake, and decide how to process it later.
Best for: Flexibility and handling diverse data types
Watch out for: Data quality and governance require extra planning.
Microservices-based pipelines
Break your pipeline into small, independent components, each doing one job (e.g., ingestion, validation, transformation).
Best for: Scalability, fault isolation, and agile development
Watch out for: Communication between services can be slow or add complexity.
Example: Let’s think aloud and choose the right framework for a ML data pipeline to predict customer churn
Let’s say you’re building an AI data pipeline to predict customer churn.
Scenario: You run a fitness app with monthly subscriptions. You track user activity, like workouts logged, sessions booked, plan changes, payment history, support tickets, and want to know who’s likely to cancel next. Ideally, you'd like to catch the early signs of disengagement and send targeted offers or nudges to retain them.
Here’s how we might think through which AI pipeline framework would fit best:
Step #1. Do we need real-time insights, or is batch enough?
For churn prediction, daily or even weekly updates might be enough. So we don’t need a full real-time streaming setup. Batch will do the job.
✔️ Batch wins here.
Step #2. Are we dealing with a lot of historical data?
Yes, churn prediction works best when we can look at patterns over weeks or months: how often someone logs in, how their activity has changed, etc.
✔️ We’ll need to store and process historical data, so ETL or ELT makes sense.
Step #3. Do we need complex transformations before training the model?
Definitely. We'll want to create features like “7-day booking streak” or “last payment issue”, which require some logic and prep before analysis.
✔️ This leans toward ETL, since we want to shape the data before it lands in the warehouse.
Step #4. Will we eventually want real-time scoring?
Possibly. Imagine someone just canceled a session, left a negative review, and had a payment fail. All within 30 minutes. That could be worth flagging in real time.
✔️ That means we might grow into a Lambda architecture setup later: batch + real-time.
The bottom line
Start with an ETL AI pipeline, possibly orchestrated with tools like Airflow and built on Snowflake or BigQuery. If you later want to score users in real time or send instant retention nudges, you can layer in streaming later, shifting toward Lambda architecture.
Build vs. buy: What’s the best way to get your data pipeline?
One of the key decisions teams face when starting with data or AI pipelines is whether to build one in-house or buy an existing solution.
Build: more control, and also more complexity
Building a custom pipeline gives you full flexibility. You can tailor it to your tech stack, your business rules, and your performance needs.
| Pros | Cons |
| Fully customizable to your unique requirements | High upfront cost and slower to deploy (6–12 months) |
| Greater control over performance, features, and security | Requires in-house data engineering expertise |
| No vendor lock-in | Ongoing maintenance and scaling can be resource-heavy |
Typical costs to build include (see how much AI costs to make in 2025):
- Initial investment: $400,000 – $1,000,000
- Annual maintenance: $80,000 – $200,000
- Training: $10,000 – $20,000Total cost over 3–5 years: $1M+
Buy: faster, easier, and lower risk
Buying a pipeline tool like Airbyte, Fivetran, or Hevo lets you get started quickly without needing to build and maintain infrastructure yourself.
| Pros | Cons |
| Much faster to deploy (1–4 weeks) | You’re limited to what the platform offers |
| Minimal engineering effort | Potential vendor lock-in and hidden costs (volume-based pricing) |
| Built-in maintenance, monitoring, and support | Customizations may require workaround |
Typical costs to buy include:
- Initial investment: $10,000 – $50,000
- Annual maintenance: $5,000 – $20,000
- Total cost over 3–5 years: $50,000 – $300,000
Making the call
A well-informed decision requires more than comparing costs. You also need to consider:
- How fast you need to launch
- Whether data pipelines are core to your product or just a support system
- What internal skills and capacity your team has
How to decide: A framework for choosing build vs. buy
If you're still unsure which path to take, use this visual framework to guide your thinking.
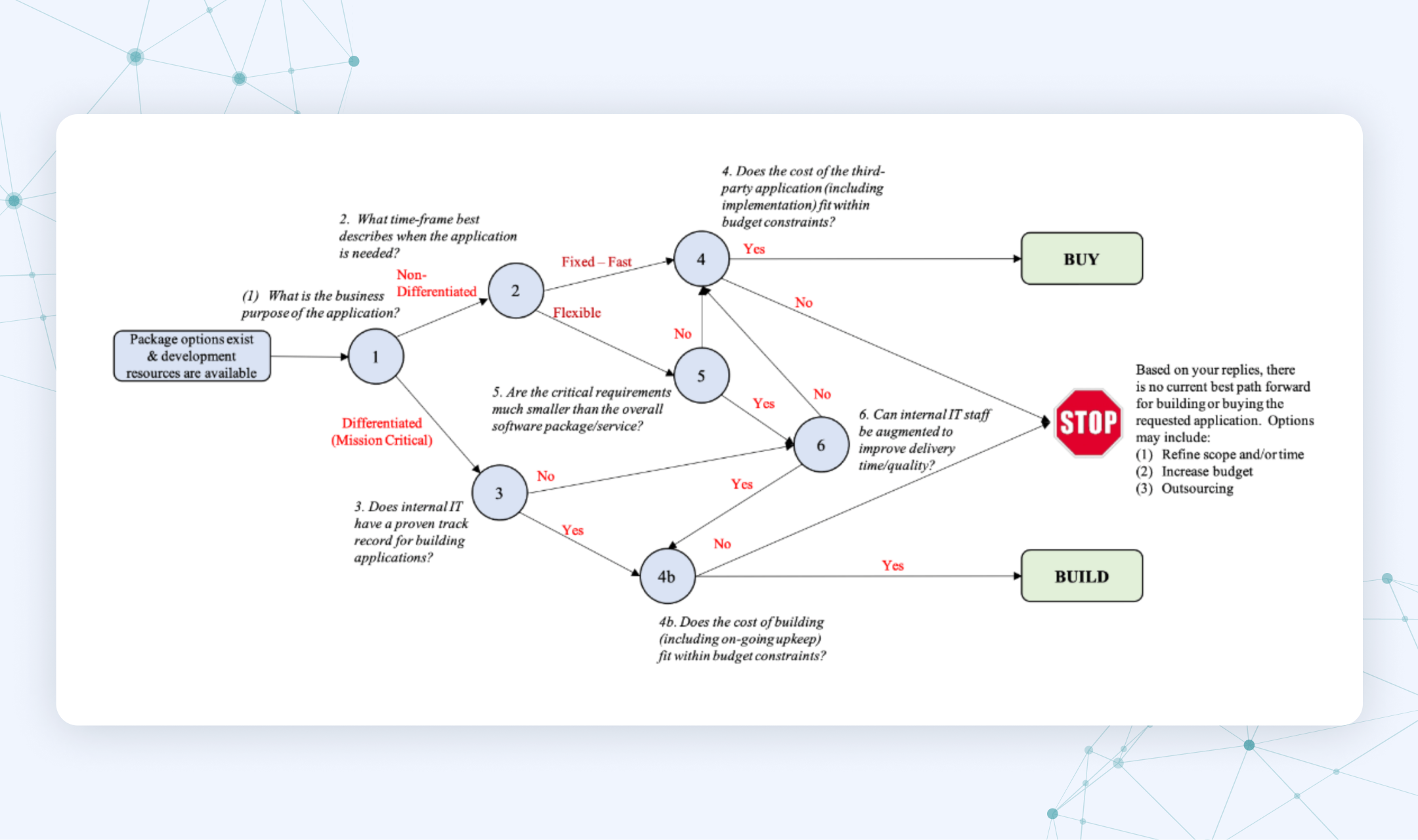
This framework walks you through key questions like:
- Is the pipeline mission-critical or a non-differentiating task?
- Does your team have experience building data systems?
- What’s your budget and timeline?
- Can off-the-shelf tools meet most of your requirements?
To sum it all up:
✔️If the pipeline is core to your product, your team has the skills, and you want full control, then building it in-house makes sense.
✔️If you need to move fast, avoid maintenance headaches, and are okay with some trade-offs, buying a solution will get you there quicker.
✔️ And if you don’t have the team in place but still need something tailored to your business, outsourcing is a great middle ground. You get custom features without having to build everything yourself.
And yes, that third option? That’s us at Flyaps :). With 10+ years of experience building data platforms and data pipeline automation tools, we know what works, and what to avoid. Feel free to book a free consultation and we’ll walk through it with you.
Frequently asked questions about data and AI pipelines
What’s the difference between a data pipeline and an AI pipeline?
A data pipeline moves and prepares data, while an AI pipeline includes extra steps like training, evaluating, and deploying machine learning models. An AI pipeline typically builds on top of a data pipeline.
How does data pipeline automation help?
Data pipeline automation makes sure your data flows reliably, from raw sources to dashboards, models, or reports, with minimal hands-on work. It’s critical for data-heavy processes, like building and maintaining AI pipelines that require clean, timely data to feed that AI pipeline.
Is a data and AI pipeline part of data processing?
Yes. A pipeline is one way to automate and manage data processing: the cleaning, transforming, and organizing of raw data so it's ready for use.




