What Is MLOps and How to Leverage It for Your Machine Learning Projects

So you’ve finally trained your machine learning (ML) model. It doesn’t hallucinate or crash under pressure. You’re proud of it. You’re ready to roll it out – only to realize you weren’t. Versioning data, tracking experiments, gluing tools together with Bash scripts…you quickly understand that building the model was the easy part.
That’s when you suddenly hear someone saying: “We need MLOps”. What is it, another pretty word invented by Gen Alpha? You wish it were.
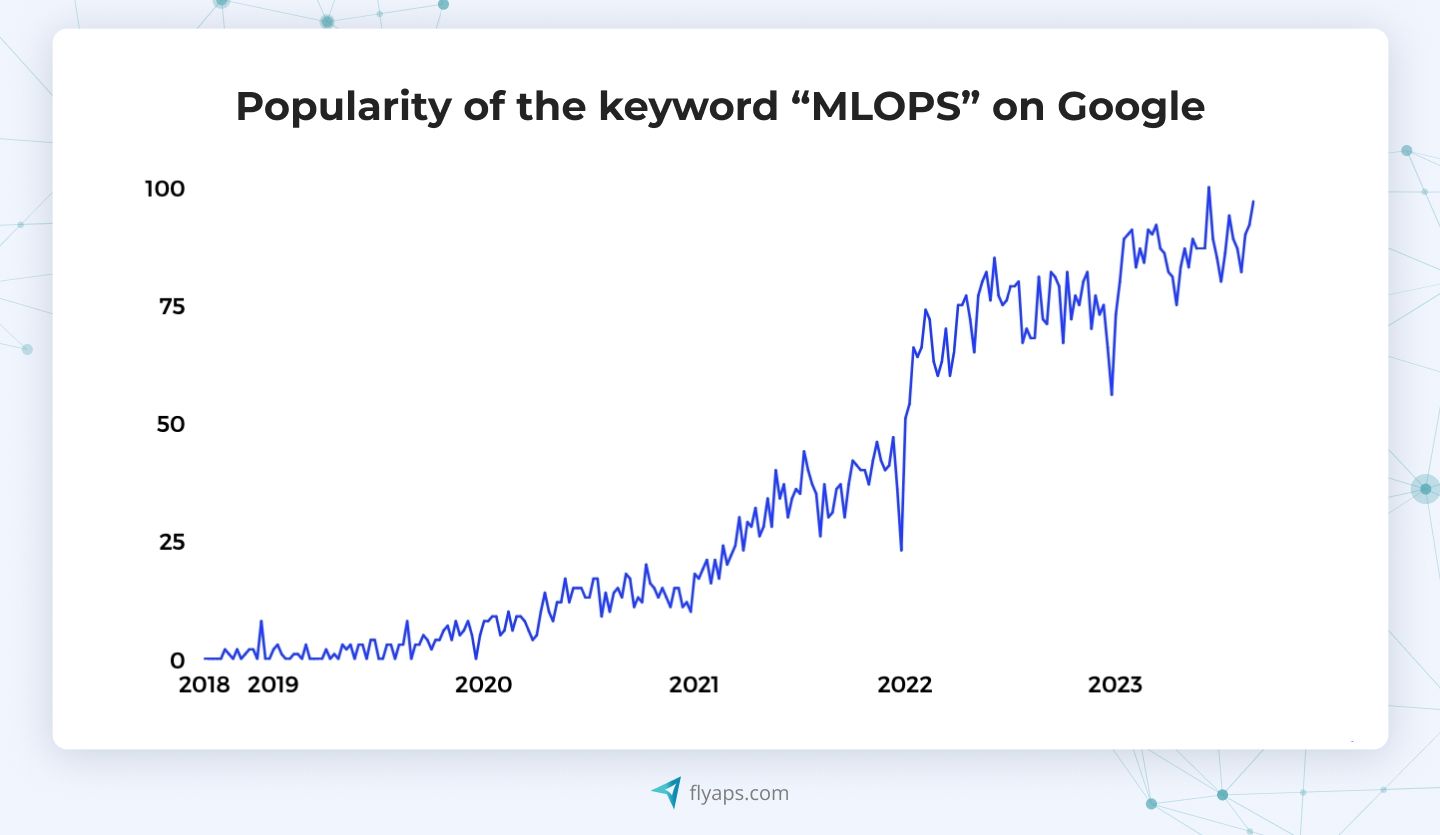
As machine learning becomes a standard part of business operations, companies are learning the hard way that getting a model to work in a Jupyter notebook is only half the battle. Making it reliable, scalable, and maintainable in production? That’s where MLOps comes in.
As an AI-focused software development team with over a decade of hands-on experience building ML products like UrbanSim and CV Compiler, we at Flyaps know this battlefield well. In this article, we’ll unpack the MLOps meaning for businesses, explore how it differs from traditional DevOps, and explain why it’s become essential for teams trying to tame the chaos of real-world ML. We’ll also share successful MLOps use cases and best practices to improve your model’s odds of making it to production.
But first, let’s define what is MLOps.
The machine learning operations (MLOps) definition
Machine learning operations(MLOps, if you’re more of an acronyms person) is a methodology designed to bring order to the chaos, automating workflows, smoothing out deployments, and making sure your brilliant ML model doesn’t die a slow, silent death before it even hits production. You might think it’s like DevOps, but as we add a machine learning lifecycle in the mix, things will never be easy.
We’ll get to that later. For now, let’s clarify what difference MLOps makes. Here's an example of a team building a recommendation system. They’ve got great data scientists, solid models, maybe even a working prototype. Without MLOps? Their process is a tangle of manual steps, last-minute fixes, forgotten datasets, and late-night Slack messages like “which version did we train on again?” It’s fragmented, messy, and not scalable.
Without MLOps, the company’s data scientists had to manually develop each machine learning model, using different tools and libraries per each. This approach led to inconsistencies and duplication of efforts.
Testing was also done irregularly, often leading to missed bugs and errors that were only discovered in production. Integrating a trained and validated model into an existing system required manual intervention, resulting in delays and potential compatibility issues. As the infrastructure for model training and inference was handled separately by the IT team, the outcome was numerous inefficiencies and resource wastage.
With MLOps practices implemented, the data science teams started collaborating using standardized tools and workflows, enabling them to develop and iterate on newly trained ML models efficiently.
MLOps also allowed to automate three crucial parts of the company’s ML project:
- Testing frameworks to reduce the risk of errors in production.
- Integration of ML models into production systems to streamline the deployment process.
- Infrastructure provisioning and infrastructure management to optimize resource usage and scalability.
The result? The company now has more streamlined model development and deployment processes and enhanced reliability with automated testing and deployment practices. The ML infrastructure can handle growing data volumes and user demands, which positively contributes to scalability.
MLOps vs DevOps
MLOps may look like DevOps with machine learning added (MLOps for a reason, right?). After all, both practices aim to streamline workflows, ensure traceability and support efficient deployment. But when we talk about MLOps, we talk about additional layers of complexity.
In DevOps, you version your code, containerize it, test it, deploy it, and monitor it. In MLOps, you have to do all that AND more. Apart from software, you’re also required to manage:
- Your data
- Your ML models
- Your hyperparameters
- Your feature stores
- Your training environments
And once your models are in production, it's not enough to simply deploy them and walk away. You also need robust model monitoring in place to ensure ongoing performance, spot anomalies, and detect concept drift early.
While it does sound similar to backward compatibility in software systems, machine learning brings a unique challenge called non-determinism. What does this mean? Models trained on yesterday’s data may behave unpredictably tomorrow if the data distribution shifts, a phenomenon known as concept drift. Without proper model monitoring, these shifts can go unnoticed, silently affecting performance over time.
Another key distinction is cross-functional collaboration. MLOps teams must bridge the gap between data scientists, ML engineers, DevOps specialists, and product stakeholders. Data scientists are driven by experimentation and insights. DevOps professionals prioritize reliability and scalability. MLOps sits at the intersection, aligning both mindsets to build models that are not only powerful but also stable, observable, and production-ready through continuous model monitoring and maintenance.
In short, MLOps builds on DevOps principles but extends them to fit the dynamic, data-centric nature of machine learning. It demands tighter traceability, specialized tooling, and end-to-end visibility, including rigorous model monitoring to ensure reliable outcomes.
Reasons to implement the MLOps process
While immensely hard to get it right, the benefits of MLOps are numerous, starting with a more structured approach for overcoming challenges like data management or model deployment to increased value of ML initiatives. Here's a breakdown of the key benefits.
1. Faster time to market
MLOps enables organizations to streamline the development and deployment of ML models, resulting in faster time-to-market for ML-powered solutions. By automating model creation and deployment processes, MLOps reduces operational overhead and accelerates project delivery, allowing companies to respond quickly to changing market demands.
2. Improved productivity
MLOps practices enhance productivity by standardizing development environments, enabling rapid experimentation and facilitating collaboration between data scientists and software engineers. By establishing repeatable processes and workflows, MLOps lets development teams iterate on ML models more efficiently, increasing productivity.
3. Efficient model deployment
MLOps improves the efficiency of model deployment and management in production environments. By integrating model workflows with CI/CD pipelines, organizations can automate the deployment process and ensure consistency across both the development or experiment environment. This results in more reliable and scalable deployments with improved troubleshooting capabilities and centralized management of model versions.
4. Cost reduction
By automating repetitive tasks and optimizing resource usage, MLOps helps organizations decrease operational costs associated with machine learning projects. By standardizing infrastructure provisioning and management, organizations can minimize wastage and improve resource utilization, leading to cost savings in the long run.
5. Enhanced model performance and quality
MLOps practices contribute to improved model performance and quality by enabling active performance monitoring, evaluation, and optimization of machine learning models in production. By implementing monitoring and governance mechanisms, companies can detect and address issues such as model degradation or concept drift, ensuring that deployed models remain accurate and reliable over time.
Want to tailor large language models to meet specific business needs? We've got you covered. Read everything you need to know in our article " Fine-Tuning Large Language Models for Custom Business Solutions ."
The benefits mentioned above vary depending on the industry where ML projects are implemented. Let's delve into the details further in and clarify what we mean exactly.
Our engineers are ready to join forces and help you bring your big idea to life.
Hire MLOps specialistsMLOps across different industries
From healthcare to finance, retail to manufacturing, ML opens up a world of opportunities for companies willing to embrace its potential. Enterprises worldwide and even small startups embrace MLOps to maximize their gains, streamlining operations, enhancing decision-making, and optimizing performance through efficient management of data, algorithms, and infrastructure.
Let's take a closer look at some industries and how they benefit from MLOps implementation:
| Industry | Flow optimization | Modeling and analytics | Predictive insights | Threat and risk management |
| Healthcare | Streamlined patient care processes, optimized hospital operations, and improved resource allocation. | Development of predictive models for disease diagnosis, treatment planning, and patient outcome prediction. | Forecast of disease outbreaks, identification of high-risk patients, and personalization of treatment regimens. | Detection of healthcare fraud, management of regulatory compliance, and mitigation of cybersecurity threats. |
| Finance | Automated financial transactions, optimized trading processes, and enhanced operational efficiency. | Development of predictive models for credit risk assessment, investment analysis, and market forecasting. | Identification of fraudulent activities, market trends prediction, and optimization of investment strategies. | Detection of fraudulent transactions, financial risk management, and regulatory compliance assurance. |
| Telecom | Optimized network traffic, improved service delivery, and enhanced customer experience. | Development of predictive models for network performance, customer churn prediction, and capacity planning. | Anticipation of network failures, identification of network congestion, and optimized network infrastructure. | Detection of network intrusions, regulatory compliance management, and network security assurance. |
| IT | Automated software development pipelines, optimized IT infrastructure, and improved deployment processes. | Development of models for anomaly detection, system failure prediction, and user behavior data analyses. | Anticipation of IT service outages, identification of performance bottlenecks, and optimization of resource allocation. | Cybersecurity threats detection, compliance risks management, and data protection assurance. |
| Public sector | Streamlined government services, optimized public transportation, and improved resource allocation. | Creation of models for crime prediction and traffic management. | Anticipation of public health crises, identification of social welfare needs, and optimization of urban planning. | Fraud detection in public services, emergency response management, and data privacy assurance. |
| Oil and gas | Optimized drilling operations, refined processes, and transportation logistics. | Development of predictive models for equipment failure, reservoir characterization, and oil price. | Anticipation of maintenance needs, identification of production bottlenecks, and optimization of exploration strategies. | Safety hazard detection, environmental risk management, and regulatory compliance assurance. |
| Retail | Optimized inventory management, supply chain logistics, and customer service processes. | Development of recommendation engines, demand forecasting models, and customer segmentation analyses. | Anticipation of consumer trends, identification of purchasing patterns, and personalization marketing campaigns. | Detection of retail fraud, inventory shrinkage management, and data security assurance. |
Now, to better understand what MLOps is in practice, let’s look at some real-life cases for you.
Real-world MLOps use cases
Let's kick things off with our own case and see how MLOps lets our client succeed in the field of urban planning.
UrbanSim: how we prepared the infrastructure for MLOps
Our company was part of the transformation of UrbanSim, a SaaS solution for city development, which is now used in various cities across the U.S., Europe, Asia, and Africa. The platform uses open-source statistical data to predict what happens after particular urban changes to help construction workers and city planners simplify the design and development of urban areas and meet community needs.

Recognizing the limitations of their legacy platform, UrbanSim was looking for a tech team to help them with a complete rebuild. We were a perfect candidate thanks to our experience in reconstructing complex legacy systems, and expertise with modern system architecture. We gathered our top specialists in backend, frontend, DevOps, and ML engineering to undertake the monumental task of rebuilding the platform from scratch, adding new features, and making it ready for ML implementation.

We enhanced UrbanSim's ability to predict urban scenarios using statistical models. Previously trained on historical data, it took a lot of time for the platform to calculate different scenarios. However, after we optimized the code and integrated the models into the system, we managed to reduce the scenario calculation time from hours to minutes. Now the system has become much faster and more efficient, with users being able to quickly create and visualize the required scenarios.

Moreover, we prepared the infrastructure for future machine learning advancements, ensuring UrbanSim is ready to embrace innovations in the field.
After our work was done, UrbanSim received a customizable, scalable, and ML-ready platform that not only meets UrbanSim's immediate needs but also enables future growth and innovation. With a 40% reduction in maintenance costs and the ability to scale and customize for diverse client requirements, UrbanSim is now equipped to embrace the transformative power of AI and ML with confidence and ease.
Ride-sharing: how Uber uses MLOps for a diverse set of applications
Uber, the world's leading ride-sharing company, leverages the MLOps process to drive data-driven decision-making across its diverse services. By implementing ML solutions, Uber optimizes services to estimate driver arrival times, match drivers with riders, and dynamically price trips. However, Uber’s ML solutions extend beyond ride-sharing to their other services like Uber Eats, Uber Pool, and self-driving cars.
Uber manages its machine learning models through an internal platform called Michelangelo, enabling seamless development, deployment, and operation of ML solutions at scale. ML models are deployed to production in three modes: Online Prediction for real-time inference, Offline Prediction for batch predictions, and Embedded Model Deployment for edge inference via mobile applications.
To ensure optimal model performance in production, Uber employs monitoring tools within Michelangelo to track model metrics and detect anomalies. Additionally, Uber applies a workflow system to manage the lifecycle of models in production, integrating performance metrics with alerts and monitoring tools for efficient operations.
Lastly, Michelangelo includes features for model governance, allowing Uber to audit and trace the lineage of models from experimentation to production deployment. This ensures transparency and accountability in model usage and management.
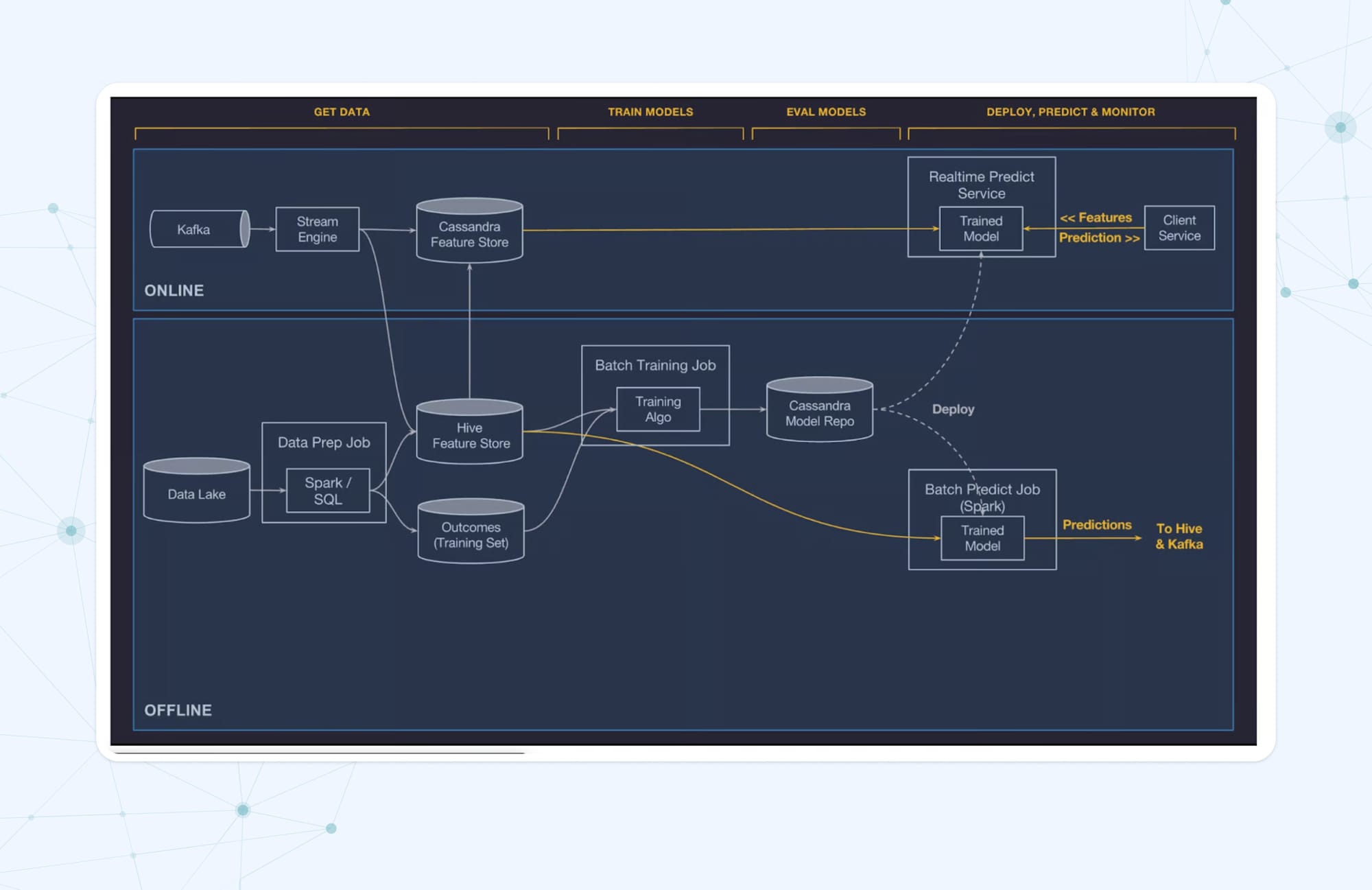
Through its adoption of MLOps, Uber has achieved enhanced decision-making, improved service efficiency, and streamlined model lifecycle management.
Data-processing: how GTS improved its data protection with the MLOps process
GTS, a leading data processing company based in Germany, has powered up its ecosystem by integrating MLOps into its operations. Specializing in Infrastructure-as-a-Service and Software-as-a-Service platforms for European companies, GTS adopted MLOps to empower its clients with enhanced compute resources, improved reproducibility, and accelerated model deployment.
For their DSready Cloud project, a centralized hub for data science and AI in the cloud, they decided to use the Domino Enterprise MLOps Platform. The platform was a great choice for meeting such GTS’ requirements as enterprise-grade security, customization, self-service infrastructure, more robust collaboration, and governance features.
Overall, Domino helps its users quickly set up computing resources while they create models. It also simplifies the creation, reuse, and sharing of work. Plus, models can be deployed much faster, sometimes within just minutes.
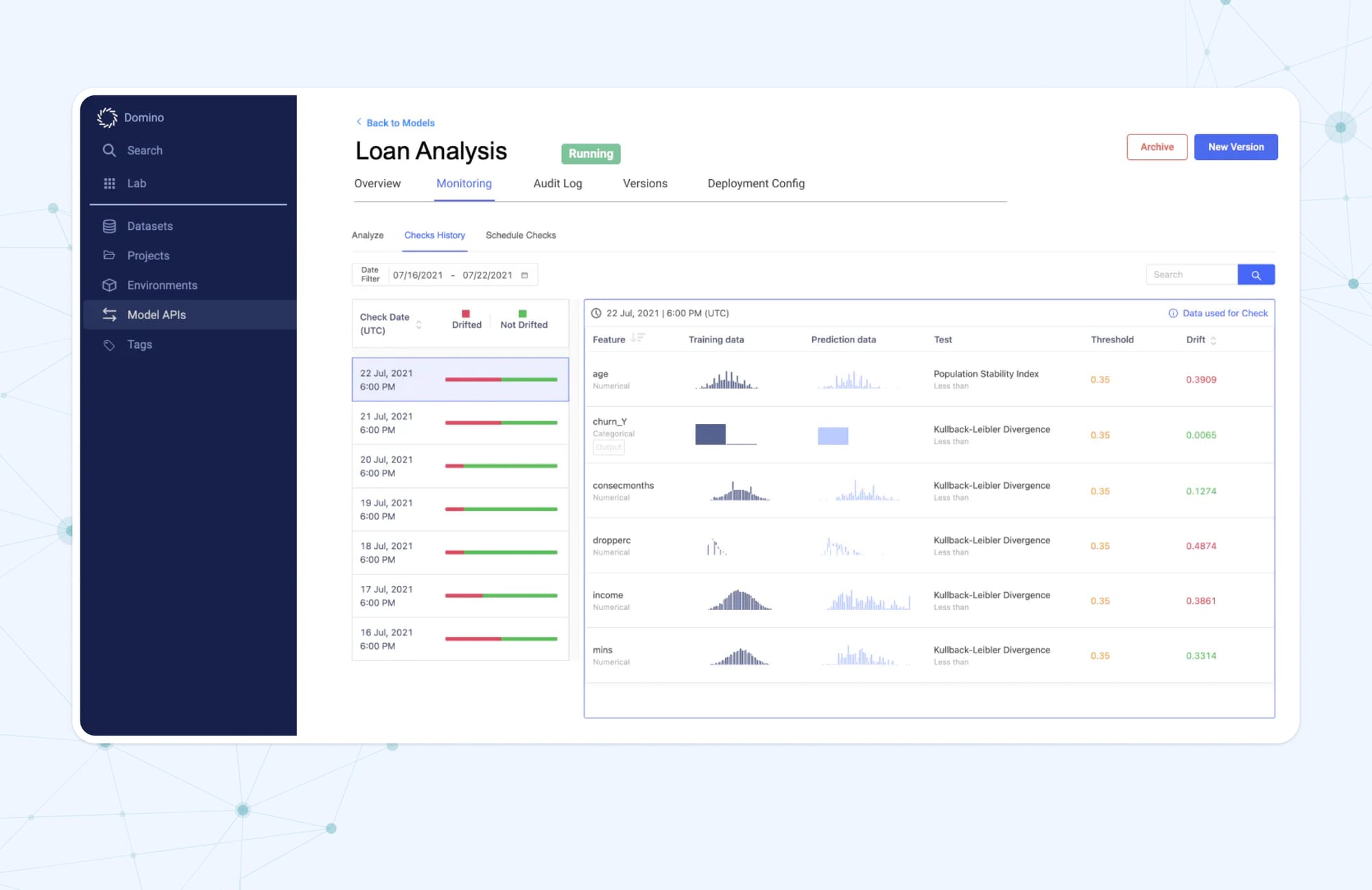
Users of the platform have direct access to all its features. This eliminates the need for any extra software or services outside of Domino’s Enterprise MLOps Platform, thereby enhancing security. Moreover, the platform enables monitoring the performance of a deployed model in production over time.
As enhanced security was the primary goal of DSready Cloud, with Domino, DSready Cloud also gained:
- Control over data. Unlike other cloud options where data might be stored on the provider's servers, Domino lets clients keep ownership while using GTS infrastructure. This ensures data stays secure and follows strict regulations.
- Top-level security. Domino offers strong security features. It has tough authentication services, like Keycloak integration, ensuring only authorized users can access the platform. SSL/TLS connections and mutual TLS add extra layers of security, keeping data traffic safe from unauthorized access.
- High-level encryption. Data in Domino is encrypted when stored and when moving around, using industry-standard methods. GTS even added more layers of encryption, including a 4,000-bit key, to ensure data stays safe.
As a result, GTS has successfully reached their goals of having smoother operations and enhanced security.
6 steps of the MLOps process (and where it hurts)
In theory, MLOps is a clean, structured process. In reality? It can quickly turn into a dumpster fire of broken pipelines, missing datasets, and tools that refuse to talk to each other. So if you want to make machine learning in operations actually work, not just in your notebook, you’ll need a reliable process.
Let’s now walk through the six core stages of the MLOps lifecycle, from preparing data to monitoring the model in production. Along the way, we’ll also point out where things tend to go sideways – because it’s really painful when it happens, so forewarned is forearmed.
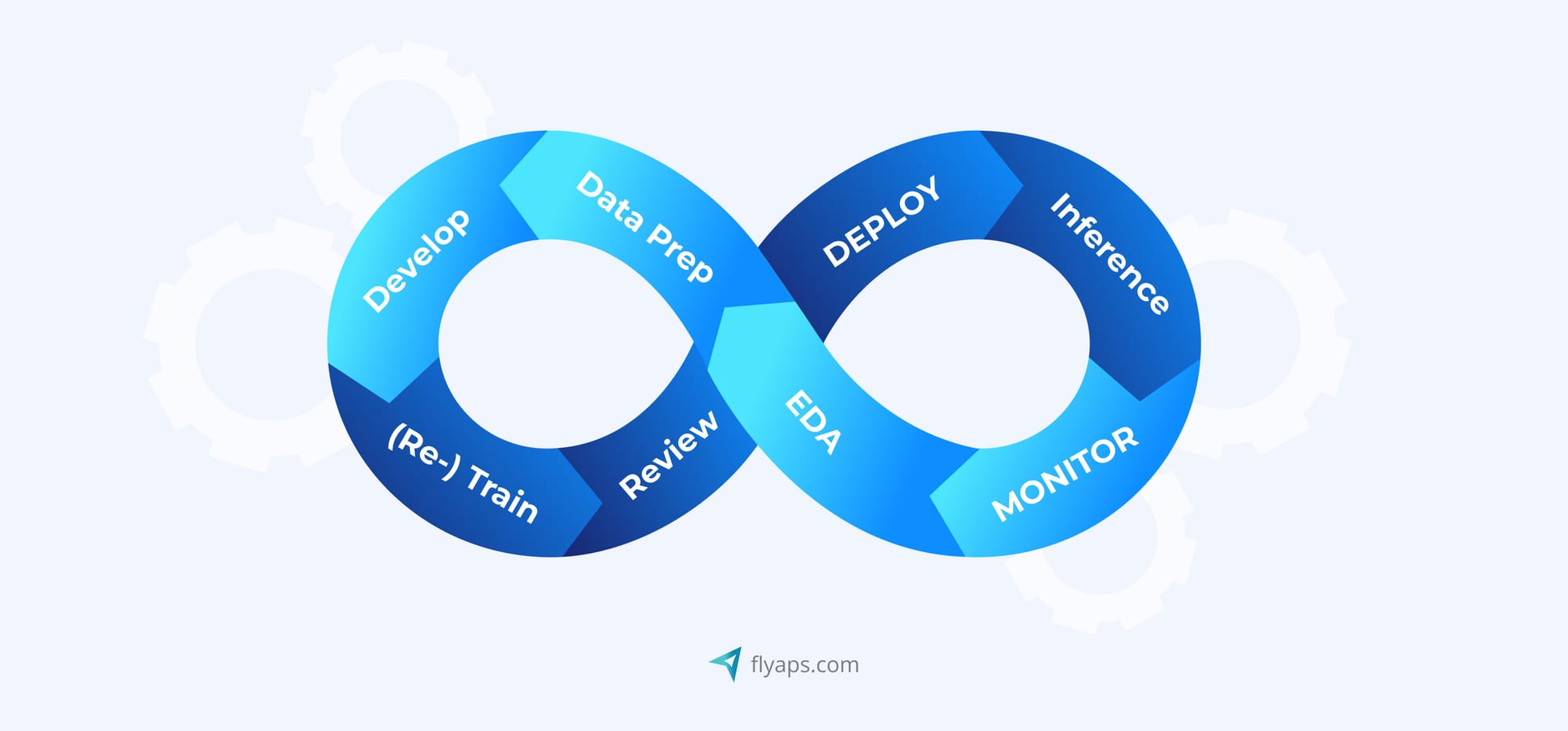
1. Data preparation
Data preparation is the first (and arguably most overlooked) step in the MLOps journey. This includes data collection, as well as cleaning and transforming the data to make it suitable for model training.
Best practices for data preparation
- Ensure data quality
Use data validation techniques to detect missing values, outliers, or anomalies early. Automated quality checks help reduce debugging nightmares downstream.
- Feature engineering
Good features = good predictions. Perform exploratory data analysis to identify and create the most relevant features for your trained model. Effective feature engineering improves model performance and ensures that the model effectively addresses the problem at hand.
- Data versioning
Here’s where MLOps gets time to shine. Keeping track of which data version was used for which model is crucial. Tools like DVC or Git-LFS let you roll back to previous datasets. Especially helpful when someone (definitely not data science teams) asks why last year’s model suddenly thinks everyone’s a cat.
2. Model training
Once the data is all set, it's time to put it to work. This is where the system learns, transforming cleaned and feature-engineered data into predictive power through algorithms, optimization, and experimentation.
But here’s where the process often goes sideways. Model training isn’t just a click-and-go event. It’s iterative, fragile, and resource-hungry. Training can take hours or even days on GPU clusters, and if you interrupt it mid-run? It can fail catastrophically. That’s why smart teams test hypotheses on smaller datasets first and rely on checkpointing to resume long training jobs without starting from scratch every time.
Best practices for model training
- Experiment tracking
To keep track of all your experiments, including the settings and performance of each one, you can use helpful tools like MLflow or Neptune. This ensures that all aspects of the experiment cycle are documented.
- Hyperparameter tuning
Hyperparameters can be thought of as knobs and dials that can be adjusted to improve your model's performance. To improve your model's performance, try testing different combinations of settings using techniques like grid search, random search, or Bayesian optimization.
- Cross-validation
Cross-validation evaluates how well your model understands the material, ensuring it can generalize to new data effectively. This is crucial for avoiding overfitting and validating the model prediction service.

Explore the top AI tools that can streamline development across industries in our article " Best AI Tools for Developers: Expert Insights and Applications for All Work Types ."
3. Model evaluation
You’ve trained a model – great job! Now’s the time to find out if it works beyond your notebook.
Model testing and validation ensure that your model performs well not just on training data, but on new, unseen data too. This stage is critical for detecting overfitting, verifying generalizability, and confirming that you’re not about to ship a model that confidently recommends ski vacations in the Sahara desert.
The goal here isn’t just to say “it worked”. It’s to prove it in a way that others can understand, trace, and trust. Because the only thing worse than a broken model is one that nobody can explain.
Best practices for model evaluation
- Select appropriate evaluation metrics that align with your specific problem and goals
Common metrics include accuracy, precision, recall, F1 score, or AUC. These metrics aid in comprehending the performance of your model across various aspects.
- Employ multiple evaluation strategies to ensure consistent performance
- Evaluate your model on separate validation and test datasets to avoid bias and overfitting, where the model is too tailored to the training data

4. Deployment
Your model is trained and validated. Time to ship it. But unlike a regular app, a machine learning model doesn’t just plug in and run – it needs to be packaged, served, and babysat.
This is where MLOps earns its paycheck. From picking the right serving method to automating rollouts and managing version control, deployment is where ad-hoc scripts and manual hacks fall apart. If you want your model to work in production (and keep working), this stage needs structure, automation, and a healthy respect for infrastructure.
Best practices for deployment
- Containerize your model
Use Docker (or similar) to wrap your model and its dependencies into a self-contained unit. This ensures consistency across environments – whether you're running locally, in staging, or in production.
- Automate deployment with CI/CD pipelines
Use tools like GitHub Actions, GitLab CI, or Kubeflow Pipelines to trigger deployments automatically after model approval, reducing human error and boosting traceability.
- Integrate with cloud platforms
To avoid a Frankenstein toolchain, many teams opt for unified cloud environments like Azure ML, SageMaker, or Vertex AI. These platforms abstract away much of the mess and let you deploy faster with built-in monitoring and rollback options.

5. Monitoring and maintenance
Just because your model is deployed doesn’t mean your job is done – far from it. Fun fact, machine learning systems can silently decay. A model that worked yesterday might start drifting today, thanks to shifting user behavior, new data patterns, or concept drift that slowly erodes performance.
This is where MLOps comes to save the day, especially for data science teams. It helps track not just technical uptime, but actual model health, surfacing issues before customers notice and giving teams the tools to retrain, alert, and adapt overall.
Best practices for monitoring and maintenance
- Monitor model performance continuously
Use tools like Prometheus and ELK stack, or create custom scripts to track how your models are doing, spot any changes in data patterns, and see how resources are being used.
- Set up automated alerts
Combine monitoring with alerting systems to notify teams when performance drops, or when input data no longer resembles training data.
- Plan for retraining
Monitoring without action is just observation. Set thresholds for when retraining should be triggered, whether based on time intervals, drift severity, or manual review.

6. Retiring and replacing models
Even the best models have an expiration date. Data drift, business changes, or better alternatives appeared on the market, every production model will eventually need to be phased out. With MLOps practices in place, this doesn’t happen chaotically for you, as you will be able to provide structured ways to monitor performance, trigger deprecation, and roll out replacements without breaking everything along the way.
Best practices for retiring and replacing models
- Avoid Frankenstein handoffs
Replace models using standardized, automated rollout processes — not last-minute shenanigans. MLOps is here to prevent exactly that.
- Use cloud-native tooling to simplify transitions
Instead of juggling half-integrated open-source tools, lean on platforms like Azure ML, SageMaker, or Vertex AI to version, replace, and retire models in a traceable, sane way, without the tribal knowledge tax.
Learn about the essential stages of AI project development, from initial concept to successful product deployment, in our dedicated article “ AI Project Life Cycle: Key Stages of Product Development Success .”
How Flyaps can help you implement MLOps (and not lose your mind down the road)
In conclusion, is MLOps magic? Absolutely not. It won’t save a broken model, fix a chaotic team, or turn spaghetti scripts into a scalable system overnight. It’s not a tool, a platform, or a silver bullet.
MLOps is a discipline, a gritty, deliberate process of making machine learning work in the real world. It means building systems that can handle decay, data drift, and changing business logic, without imploding when your chatbot calls a customer by the wrong name. It means:
- Catching model failures before your users do
- Rolling back everything (even the data) when things go wrong
- Setting up alerts that fire before your KPIs drop
- Designing infrastructure that holds up even when the model doesn’t
And yes, it’s hard. There’s no shortcut.
That’s where we come in.
Our AI development company has spent over a decade helping teams get real about machine learning in operations. We build production-grade ML pipelines, automate CI/CD workflows, implement drift monitoring, and help businesses roll out and retire models without fear. We’ve supported over 100 companies worldwide, including enterprise players like Yaana Technologies, in developing ML-powered solutions that scale.
So whether you're starting from scratch or drowning in disconnected tools, we can help you build something robust, without sacrificing flexibility.
Book a free consultation with our experts, and let’s have your MLOps done right.
Let’s talk

