Generative AI Tech Stack: A Complete Guide

The rise of ChatGPT has sparked considerable enthusiasm for generative AI, resulting in an increased demand for this technology. All businesses related to gen AI are witnessing substantial growth. Take Nvidia Corp, for example. The company makes about 80% of the chips called a data-center accelerator, which is responsible for enhancing the performance of data centers and gen AI, in particular. In just eight months, their stock prices went up three times, and for a little while, they were worth $1 trillion, standing next to giants like Apple, Alphabet, Microsoft, and Amazon.
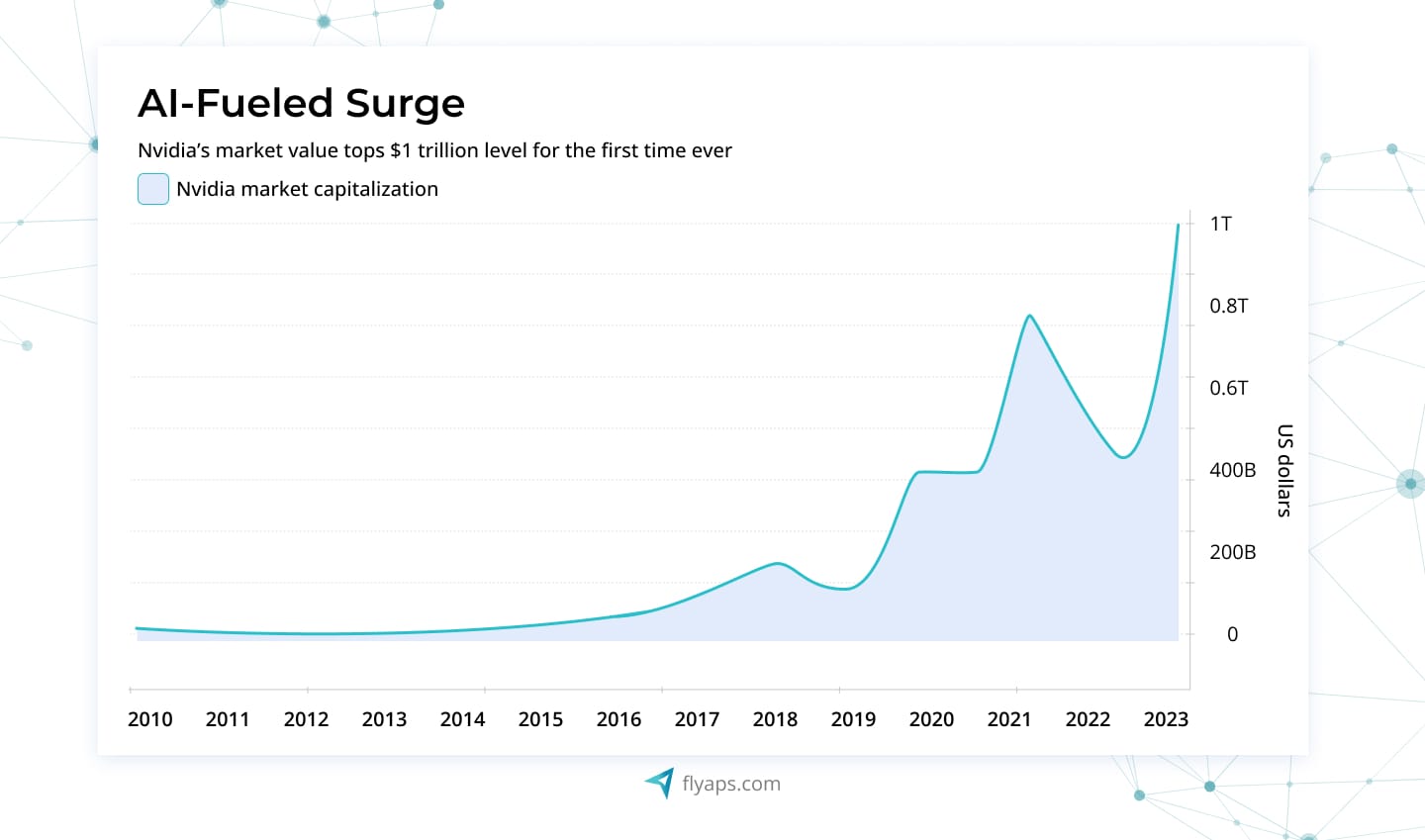
Being an AI-focused software development company, we at Flyaps closely monitor this industry dynamic. Having contributed to various AI projects, from the innovative CV Compiler to the easy-to-use GlossaryTech Chrome extension, we believe that success in harnessing the power of generative AI lies in making the right technology choices.
Understanding how the generative AI technology stack works is essential for developing effective solutions in the generative AI domain. In this article, we aim to demystify the complex generative AI tech stack in simple terms. We will concentrate on the four crucial aspects necessary for generative AI solutions and guide you through the top technologies used to build them. But let’s start with the definition first.
What is the generative AI stack?
In a nutshell, generative AI is а mix of various methods and technologies carefully combined to make artificial intelligence systems capable of creating new content or data. These systems undergo training on existing datasets, empowering them to generate unique outputs by tapping into patterns and structures acquired during their learning phase.
The generative AI tech stack is a detailed breakdown of the tools, technologies, and frameworks commonly employed in the development of AI systems. This stack serves as the foundation, guiding the construction of generative AI, and plays a pivotal role in transforming theoretical concepts into tangible, innovative outputs.
The generative AI tech stack consists of application frameworks and a tooling ecosystem we can divide into four layers, which are models, data, evaluation and deployment. Let’s dive deeper into each of these tech stack parts.
Application frameworks for gen AI tech stack
Application frameworks majorly contribute to the generative AI tech stack by assimilating innovations and organizing them into a streamlined programming model. These frameworks simplify the development process, providing developers with the ability to quickly refine and improve their software in response to emerging ideas, user feedback, or evolving requirements.
Gen AI is a recently emerged technology, but there is already a wide array of proven frameworks:
LangChain
LangChain is an open-source focal point for developers navigating the complexities of foundation models. It provides a collaborative space and resources for developers working on generative AI projects.
Fixie
Fixie is an enterprise-grade platform dedicated to creating, deploying, and managing AI agents. It focuses on delivering robust solutions tailored to the needs of businesses, contributing to the seamless integration of generative AI technologies in various industries.
Semantic Kernel: developed by Microsoft, this framework enables developers to build applications that can interpret and process information with a deeper understanding of context.
Vertex AI
Vertex AI is a Google Cloud product that provides a platform for creating and deploying machine learning models with ease.
Griptape
Griptape is an open-source framework for building systems based on large language models (LLMs) - neural network models designed to understand and generate human-like language patterns on a large scale, part of natural language processing (NLP). It's really handy for building conversational apps or event-driven apps.

Models
The traditional method for developing AI models is to build them from the ground up. However, the past five years have witnessed the emergence of a revolutionary category known as foundation models (FMs). These FMs serve as the beating heart of generative AI technology, seamlessly performing human-like tasks such as crafting images, generating text, composing music, and producing videos.
Developing generative AI solutions introduces a dynamic interplay with multiple FMs, each offering distinct features in terms of output quality, cost, latency, and more. Developers have three options to choose from for their generative AI tech stack: leveraging proprietary models from vendors like Open AI or Cohere, exploring open-source alternatives such as Stable Diffusion 2, Llama, or Falcon, or opting to embark on the journey of training their own models.

Hosting services, fueled by innovations from companies like OctoML, now offer developers the flexibility not only to host models on servers but also to deploy them on edge devices and browsers. This significant leap forward not only enhances privacy and security but also drastically reduces latency and operational costs.

When it comes to training, developers are empowered to shape their own language models using a spectrum of emerging platforms. Several of these platforms have given rise to open-source models, providing developers with readily accessible and customizable solutions out of the box.

Data
To train models, particularly LLMs, they need to be “fed” with huge amounts of data. To harness the potential of data, developers employ the following approaches to connect and implement this invaluable resource.
1. Data loaders
Data loaders facilitate the efficient loading and processing of datasets, ensuring that the model has seamless access to the necessary information, and acts as the bridge between raw data and the generative AI model.
Developers use data loaders to handle tasks such as data normalization, transformation, and batching. These mechanisms optimize the model's ability to learn from diverse datasets while maintaining consistency and efficiency.

2. Vector databases
In the context of generative AI tech stack, vectors are crucial as they encapsulate the essential features of the data in a compressed form and play a pivotal role in storing and managing vector representations of data.
Vector databases are needed to efficiently retrieve and manipulate vectorized data during the training and inference phases. This ensures that the model can quickly access relevant information, enhancing its ability to generate coherent and contextually relevant outputs.

3. Context windows
They encapsulate the contextual information surrounding a specific data point, providing a framework for the model to understand relationships and patterns and define the scope of data that the generative AI model considers during its operations.
For selecting an optimal generative AI tech stack, developers define context windows to influence the model's understanding of sequential or relational data. This enables the model to generate outputs that exhibit a deeper understanding of the context in which they are applied.

Evaluation
For developers working with large language models within generative AI technology, the performance phase is critical. Here, a delicate balance must be struck between model performance, inference cost, and latency. This requires setting clear metrics, creating meticulous test sets, and engaging in iterative testing, both manual and automated.
However, measuring performance in the realm of LLM is no easy feat. LLMs produce uncertain outputs based on probabilities and statistical patterns learned during training. This creates uncertainty as the model doesn't produce deterministic results for a given input.
Additionally, certain language tasks, such as generating diverse creative content, don't have a single correct answer. The model can produce different outputs for the same input, adding a layer of complexity to measuring its performance, making the performance evaluation more complex.
Developers have three techniques to handle the complexity of the evaluation layer: those provided prompt engineering, experimentation, and observability.
Prompt engineering tools
Prompt engineering is about creating accurate questions or instructions to direct generative AI models toward particular results. It is the essential connection between human input and machine responses. In assessing generative AI, it's crucial to engineer prompts that shape model behavior, improve outputs, optimize prompts for desired outcomes and ensure effective communication between humans and AI.

Tools for experimentations
Experimentation in the context of the generative AI tech stack involves ML engineers conducting methodical experiments to understand how adjustments impact model behavior and performance before releasing the project. They carefully track changes to prompts, hyperparameters, fine-tuning configurations, and model architectures.
Before implementing models in real-world scenarios, it is crucial to evaluate them offline in controlled staging environments. Here, engineers use benchmark datasets, human labelers, or even generative models (LLMs) to create diverse scenarios that help them evaluate and improve model responses. But while offline methodologies provide some insights, they have limitations. For instance, they may not completely capture the ever-changing and unpredictable nature of real-life situations, and relying on benchmark datasets during offline evaluations might restrict the model's exposure to a small range of examples.
This is where tools like Statsig come in. They allow for the evaluation of model performance in production, ensuring that models behave as expected during live user interactions.

Observability tools
Once an application is deployed in a production environment, the journey is still far from over. That is where the observability process begins.
Observability involves collecting, analyzing, and visualizing data related to the application's behavior, performance, and interactions after the model has been deployed. When applied to generative AI technology, it allows developers to gain essential insights into how their AI models are functioning in real-world scenarios. This ongoing process is crucial for several reasons.
Firstly, observability in generative AI technology connects developers' knowledge of how their applications perform with infrastructure data. This helps them gain necessary insights into intricate distributed cloud infrastructure systems such as Kubernetes.
Secondly, tracking the behavior of the model over time is essential for identifying any deviations or unexpected patterns that may emerge. This real-time feedback loop enables proactive measures to be taken to address issues before they escalate, ensuring a smooth and reliable user experience.
To facilitate this post-deployment monitoring and analysis, platforms like WhyLabs have introduced tools such as LangKit. LangKit is designed to offer developers a comprehensive view of the quality of model outputs. It goes beyond basic metrics, providing insights that help developers understand the intricacies of model performance.
Additionally, LangKit serves as a safeguard against malicious usage patterns.

As we've touched on development and the tools needed for evaluation, let's highlight additional tools in the generative AI tech stack required for successful generative AI product development.
Generative AI tech stack for deployment
Once developers reach the critical stage of deploying their applications into production, they are typically faced with a deployment strategy decision. There are two primary approaches developers can take to get their apps into a live environment: self-hosting and using third-party services.
Self-hosting (with frameworks like Gradio) empowers developers with the autonomy to manage and control their application's deployment process. They set up and maintain the necessary infrastructure, which provides a high level of customization according to their specific requirements.
Third-party services (like Fixie) offer a streamlined and often more straightforward deployment process. Developers leverage external AI development platforms to handle aspects like server management, scaling, and maintenance, allowing them to focus more on the application's functionality.

Flyaps’ approach to the gen AI stack selection
Generative AI is a new and advanced technology that leads the field of artificial intelligence. However, it is still a part of the wider domain of AI and shares the basic principles of machine intelligence. With over ten years of dedicated experience in AI software development, our team has developed a precise and sophisticated approach to assisting clients in selecting the technological foundation for their projects. Here are the details.
1. Project analysis and technology alignment
We kick things off with a detailed analysis of the project's scope, ensuring a thorough understanding of the requirements, goals, and constraints of the project before making any tech decisions. Our focus is on tailoring the technology choices with our team’s technical capabilities. This initial step lays the foundation for a strategic and well-informed tech stack selection.
2. Boosting performance through leveraging hardware
Moving forward, we leverage available GPUs or specialized hardware to empower our chosen computational frameworks. This strategic move is geared towards ensuring superior performance in our generative AI projects. By aligning our technology with robust hardware, we enhance the capabilities of our frameworks for optimal results.
3. Robust support system and scalability
Another crucial aspect of our approach is the establishment of a robust support system. This encompasses comprehensive documentation, tutorials, and community assistance, creating an environment for efficient troubleshooting.
As we progress, scalability takes center stage, where a smart selection of distributed computing frameworks becomes instrumental in handling large datasets effectively. By prioritizing both support and scalability, we guarantee a strong and flexible base for our generative AI projects.
4. Security and compliance assurance
In our final stages for selecting a generative AI tech stack, we prioritize information security and generative AI compliance as extremely important. We implement robust measures, including strong encryption, role-based access, and data masking, to secure our generative AI projects. Model security safeguards our intellectual assets, and cybersecurity tools fortify the infrastructure against potential threats. We firmly follow industry-specific regulations like HIPAA and PCI-DSS to ensure the secure and responsible implementation of generative AI in our projects.
Let us help you choose - explore our skills and reach out and get expert advice.
Let’s collaborateIf you want to learn more about our expertise, check out our AI development services to see how we can help bring your AI projects to life.




