Generative AI Models Explained: Types, Use Cases, and a Decision-Making Process

By the end of 2024, 85% of business leaders surveyed by MIT and Telstra plan to integrate generative AI in some of their organization’s operations. But even though businesses understand the myriad benefits this technology brings to the table, not many of them truly get how to implement it. This is especially true when we are talking not about the general concept of 'generative AI', but the actual generative AI models. How many of these models are there? How do they differ? Which one should you choose and which one to reject?
At Flyaps, we’ve helped numerous companies from various sectors with artificial intelligence. So, we can provide insights on these topics and more. This article explores the best generative AI models designed for various purposes and factors to consider when choosing a model for your project.
What are generative AI models?
Learning the generative AI models' mechanics helps with further evaluations.
Generative AI models act like students learning from large books of examples. They use "probabilistic modeling" to analyze these examples. Instead of memorizing, they calculate the likelihood of scenarios and how they fit together. By adjusting their learning or tweaking settings, developers can guide them to perform tasks in various ways.
For instance, a generative AI model can train on a large dataset of physics books, using the data to generate new text and assist students with complex topics.
For example, when students request information on string theory, artificial intelligence analyzes sentences from its training data. It finds semantically related words and their patterns. It identifies word pairs like "quantum" and "mechanics" or "string" and "theory." Based on these patterns, artificial intelligence calculates word arrangements and generates a new sentence related to string theory. The model generates a sentence using data related to string theory in a logical manner.
The core concept behind generative artificial intelligence is simple. Multiple generative AI models are needed because each handles specific tasks depending on the domain and has unique data and accuracy requirements. AI development platforms play a key role in supporting this diversity by providing the infrastructure and tools needed to build, test, and deploy these models efficiently.
Let's take a closer look at some types of generative AI models.
Types of generative AI models
Simply put, types of generative AI models are approaches to generating new content. They’re like digital toolboxes for creating new things like text, images, music and video. Many new tools are appearing every day as developers experiment with them. We will only mention the most popular types of generative AI models in 2024.
Large language models (LLMs) and Small language models (SLMs)
Large language models power artificial intelligence tools like ChatGPT and Claude, mainly for text generation. However, GPT-4 and some Gemini models can also process images, a rare ability for language models.
LLMs train on large datasets and use transformers, specialized neural networks, to mimic the tone and writing style of their training data. This technology creates chatbots, generates code, and assists in tasks like DNA research or sentiment analysis for search engines.
There's a smaller and more resource-efficient alternative to LLMs called small language models. Hugging Face CEO Clem Delangue recently shared his thoughts on SLMs, saying, “My prediction: in 2024, most companies will realize that smaller, cheaper, more specialized models make more sense for 99% of AI use cases. The current market & usage is fooled by companies sponsoring the cost of training and running big models behind APIs (especially with cloud incentives).”
SLMs perform similar functions to LLMs but use less computational power and require less training data. Although not as effective for complex tasks, they excel in simpler applications such as mobile apps and IoT devices. This efficiency makes SLMs an excellent foundation for building a responsive and cost-effective AI Agent that can operate directly on edge devices. SLMs are also easier to customize. Adapting an LLM to specific requirements demands substantial resources, while an SLM suits smaller-scale needs.
Even major LLM providers like OpenAI recognize the potential of SLMs. Recently, OpenAI introduced GPT-4o Mini, claiming it outperforms other small models in reasoning tasks, achieving an MMLU score of 82%.
AI can do more for your business—let’s find the best way to make it work for you. Check out our expertise and let’s discuss your next AI project.
See our AI servicesGenerative adversarial networks (GANs)
GANs are used for changing images in various ways (from style to color or content) or synthetic data generation (for training other models).
GANs work based on two neural networks – the generator and the discriminator. The generator creates fake poor-quality images, while the discriminator distinguishes between real and fake images made by the generator.
Basically, the two networks play a game against each other: the generator tries to produce data that is indistinguishable from real data, while the discriminator tries to get better at telling the difference. This back-and-forth duel continues until the generator creates realistic data that the discriminator can't differentiate from real data.
Transformer-based models
These models have replaced the earlier deep learning types for pattern recognition, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs).
CNN and RNN types require large, labeled datasets to train their models. Their adoption was costly and time-consuming. The transfer-based architecture has been able to overcome those challenges. Instead of relying solely on labeled data, they employ mathematical methods to identify patterns between elements. This innovative technique removes the necessity for extensive labeled datasets. Their improved architecture is based on attention mechanisms that focus on different parts of the input data when processing it. For example, the system processes each word and weighs its importance to better capture dependencies and relationships between words.
Such an approach is ideal for sequential data and tasks like sentiment analysis, machine translation, speech recognition, image captioning, image generation and object recognition.
Variational autoencoders (VAEs)
VAEs support unsupervised learning, allowing the algorithm to identify patterns without guidance. They generate new data similar to the training set, such as realistic images of faces, animals, or scenery.
For instance, Meta's Reality Labs, which is focused on the development of augmented reality (AR) and virtual reality (VR) technologies, uses VAEs for creating detailed face models. The model can be used for facial recognition, animation, virtual reality, medical imaging, and security systems.
VAE models consist of two main parts: an encoder and a decoder. The encoder takes input data, compresses it and keeps its essential features in the space called “latent”. The decoder takes a point from the latent space and reconstructs the original data from it. It learns to generate data similar to the input data based on the information in the latent space.
Neural radiance fields (NeRFs)
NeRFs can create a 3D picture from only a few 2D pictures by figuring out how much density is in each point in space and what color it should be. Naturally, their applications include virtual reality, augmented reality, and 3D content creation.
The core concept of generating new information from learned data can be implemented through various approaches, depending on the required goals or features. Now, let’s explore some examples.
The most popular generative AI model examples for 2024
When people talk about generative AI models, they usually mean a collection or group of models. Take GPT, for instance. The GPT series consists of several versions ( GPT, GPT-2, GPT-3), each with increasing model size, complexity, and capabilities.
Models resemble a family tree with different generations and branches. The GPT series evolved from LLMs and transformer-based models, which act as the grandparents. Types are split into smaller groups — sets (parents) — and each set includes individual models (children). Unlike humans, each new model is always an improvement over its predecessor.
Since GPT is mentioned, let’s begin our list of the top generative AI models with it.
GPT (generative pre-trained transformer)
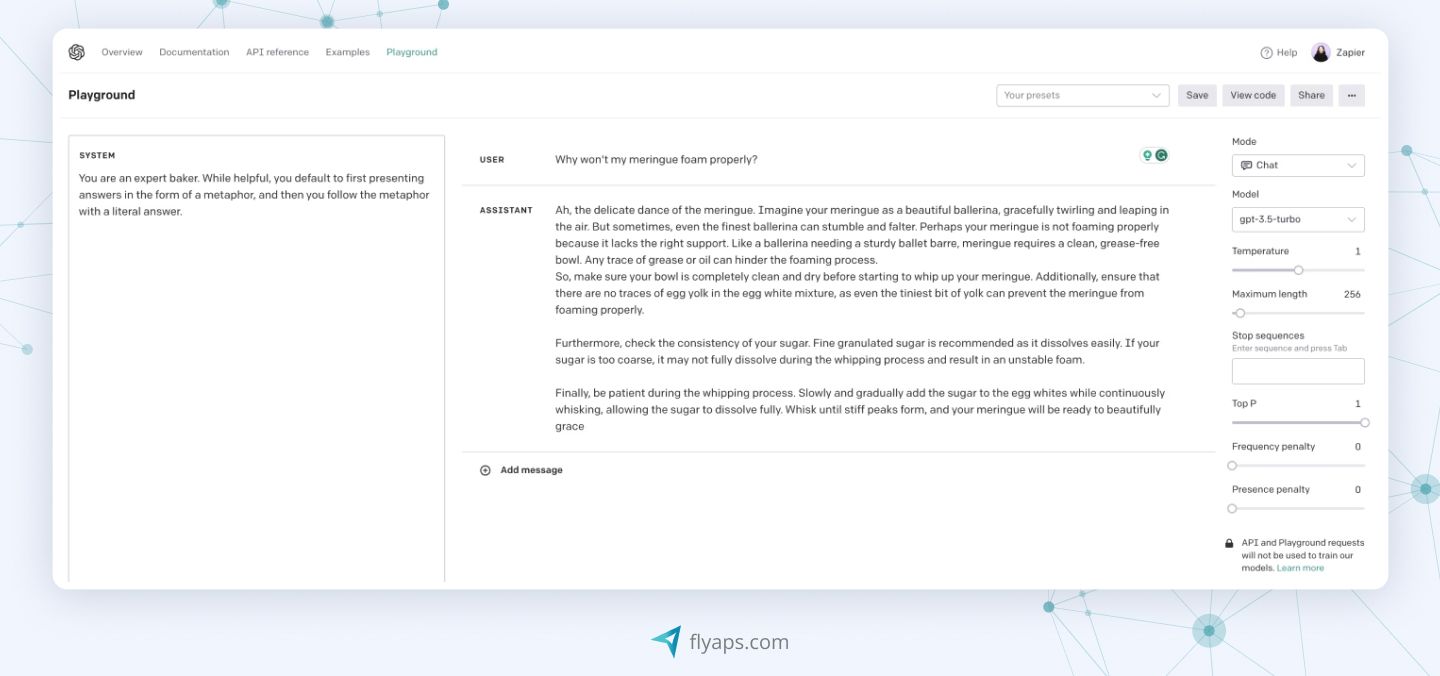
Developed by OpenAI, the GPT series is both an LLM and transformer-based. GPT models fall into two categories: general and custom. GPT-3.5 and GPT-4 are examples of general models. Custom GPT functions as a personalized version of ChatGPT. Users can select specific features, adjusting data and instructions to fit their needs.
Here’s what general GPTs can do:
- Generate code in different programming languages.
- GPT-4 can generate images.
- Improve itself based on users’ feedback.
Curious to learn more? Read our article for details on GPT's pros and cons and the 6 other best LLMs for your business .

Stable Diffusion
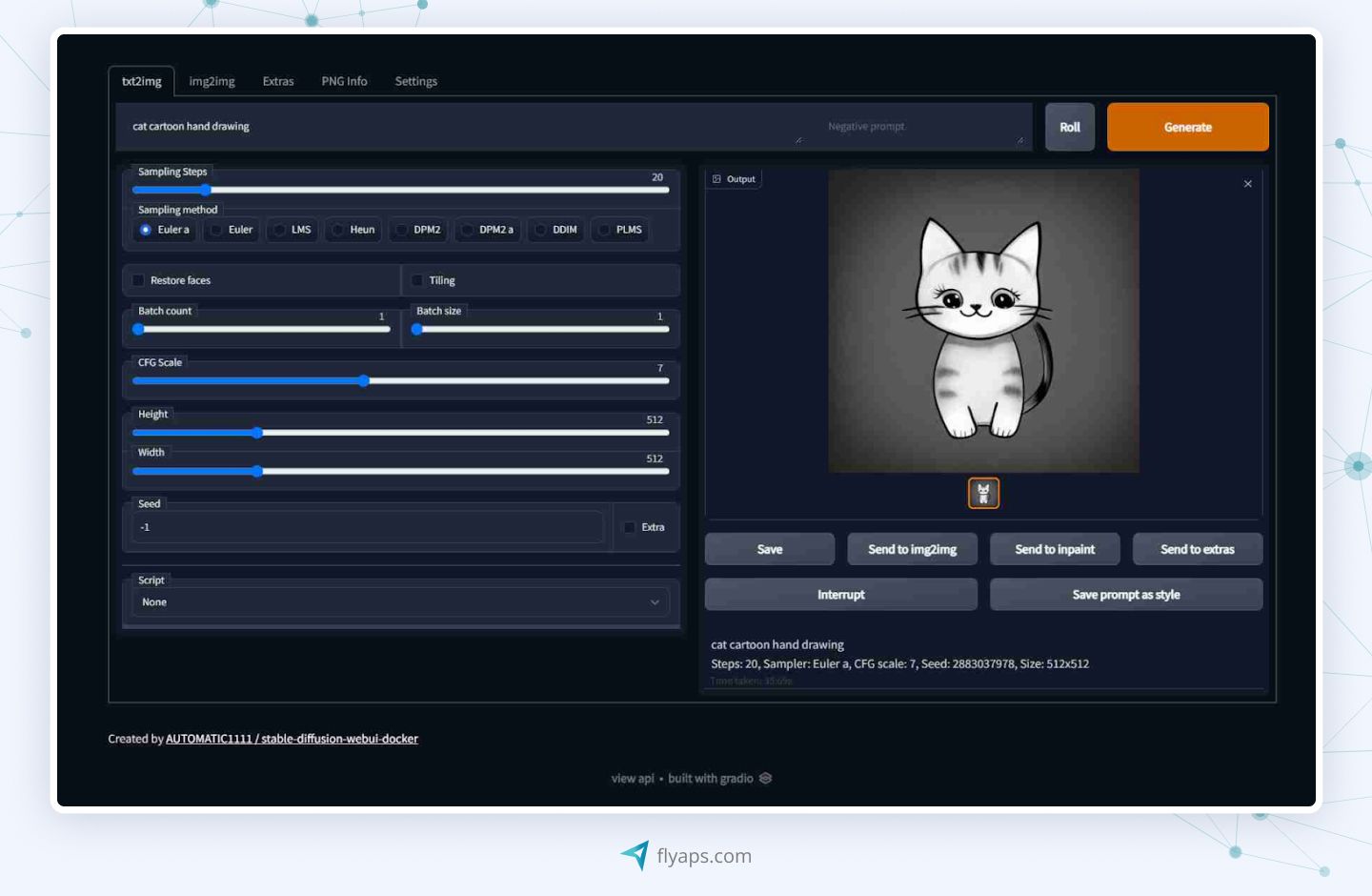
Stable Diffusion is a suite of models with Stable Diffusion 3 being the latest and most advanced. It is open-source, allowing users to train generative AI models to generate realistic images from text descriptions.
Users can set it up locally or access it via platforms like Clipdrop and DreamStudio to produce high-quality images by providing detailed instructions on subject, style, and mood.
While Stable Diffusion models produce impressive results, their drawback lies in their computational cost and resource requirements. Generating high-quality images typically requires significant computational power and time.
LaMDA

LaMDA is a transformer-based model developed by Google for conversational applications, making it a powerful engine for creating a sophisticated AI Chatbot that generates human-like responses. It generates human-like responses in natural language. While it sounds like another chatbot model, LaMDA is more advanced in terms of the variety of topics it can carry on a conversation about. And the level of fluency is quite high – Google has put a lot of effort into making the model talk like a friend, not a robot, and encourage conversation.
Hugging Face’s BLOOM

BLOOM is an autoregressive LLM, meaning that it generates output sequentially, token by token, where each token depends on previously generated ones.
The model aims to fill in missing sections of text or code. BLOOM excels at specific tasks, such as code generation or natural language completion, but its range of application is limited to these concrete tasks only, unlike more general AI models.
Meta’s Llama
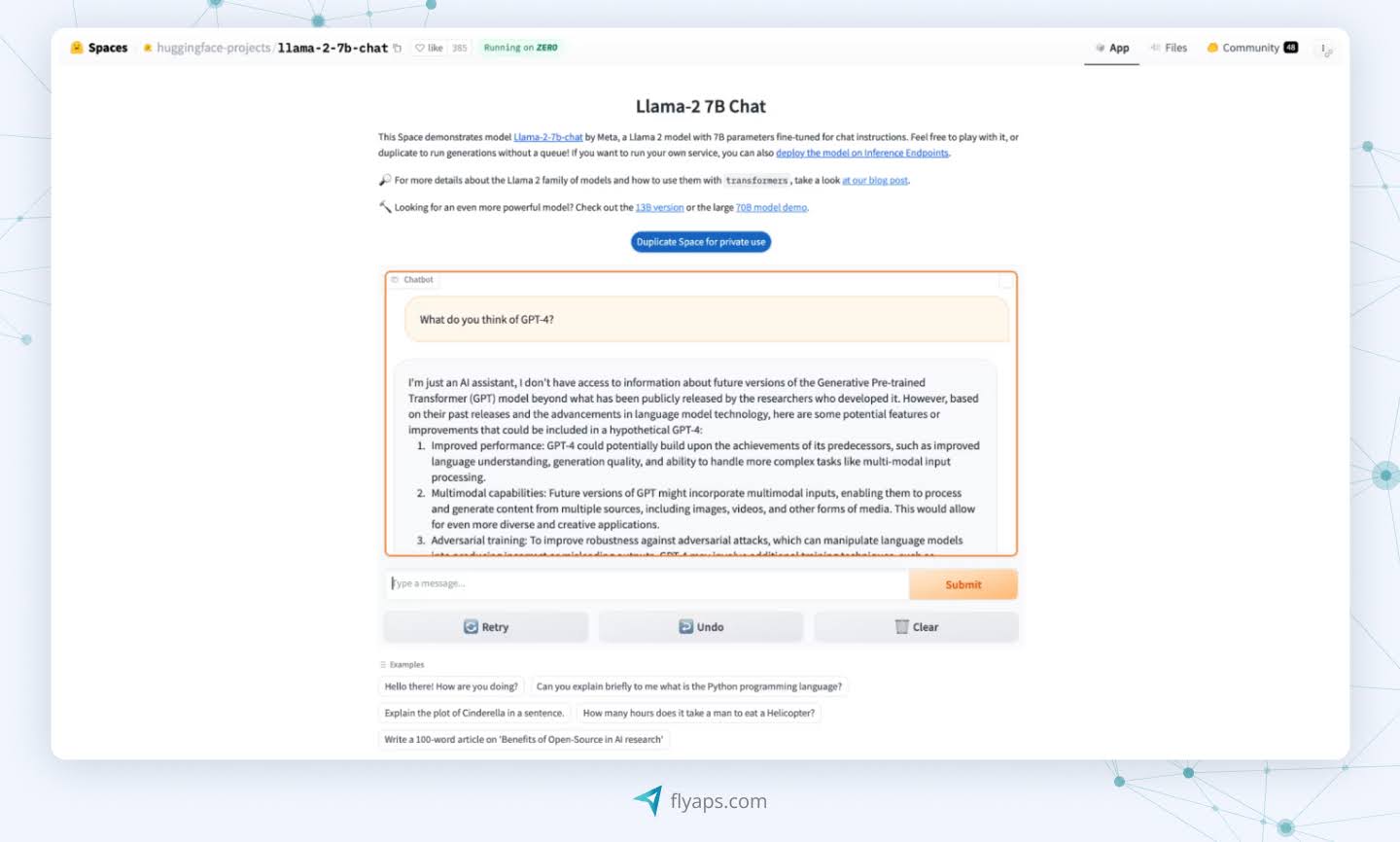
These models come in different sizes, so Llama can work on everything from small phones to large cloud systems. Meta used it to create its artificial intelligence assistant, which you can check out on its social media platforms. The model is often used to generate text or code.
An important plus for Llama is its community support. Although Meta does not disclose all the details of its training data, users can still access resources provided by the company itself or other developers. These resources may include documentation, tutorials, and forums where users can share knowledge and best practices for using the model.
No universal model fits all needs. Avoid limiting your search to lists of popular generative AI models. Here’s how to define your requirements and select the right generative AI model.
How to choose the right generative AI model
Before proceeding, it’s important to clarify that selecting the best generative AI model for your AI project is best done with input from professionals experienced in generative AI algorithms. Their hands-on experience can align your business needs with the right technologies and approaches for optimal outcomes. If you prefer to proceed independently, here’s a general decision-making process.
Step 1. Define the key feature to perform
Choose the specific task or problem you intend to solve. Define what exact features of generative AI models can help you to achieve the goal. Is there any cheaper or ready-made solution you can use instead of artificial intelligence for this purpose? If not, move to the next step.
Step 2. Evaluate what model’s size the existing ecosystem can handle
Larger models often offer more features but require more computing resources. So gather information about each generative AI model that performs the functions you're interested in, including its size, performance metrics, and the computing resources required to deploy and run it.
Step 3. Evaluate the performance
Define specific performance benchmarks like accuracy or speed, and evaluate the outcome each model can provide. For instance, one model might be accurate but slow, while another is faster but less precise.
You can assess models even if you’re not currently using them. Review data and reports from reputable sources to assess each model’s real-world performance. Check metrics like precision, recall, and F1 score for accuracy in identifying and classifying inputs. For speed, consider metrics such as inference time or processing time per input to see how quickly the model produces results.
Step 4. Assess risks and governance
Consider the risks of using each model. Are there potential biases or ethical concerns in the content generated? Ensure that the chosen model is ethical and follows governance policies.
Step 5. Consider the costs of the model and your budget constraints
Some models may be more expensive to deploy or maintain than others. This could include licensing fees, infrastructure, support and training. Even open-source models cost money to set up and run. This may involve setting up and configuring the model, as well as maintenance and updates.
Curious about pricing factors and real costs? Read our article How Much Does AI Cost?
 Natalia Palamarchuk
Natalia Palamarchuk
Use pre-built solutions to simplify gen AI models adoption
Embracing generative AI doesn't have to be complicated. To implement it, we at Flyaps offer pre-built artificial intelligence solutions designed for various industries. These solutions can be easily customized to fit your specific needs, eliminating the need for extensive decisions about model selection or integration with existing systems.

Anyway, working with models is an ongoing job, as the technology changes rapidly and newer versions appear every day. So find reliable experts with experience in the field to help you keep your finger on the pulse and ensure that your solution is not outdated at the development stage.
Having trouble finding a reliable team to explore generative AI? Drop us a line!
Skip the endless hiring cycles. Scale your team fast with AI/ML specialists who delivered for Indeed, Orange, and Rakuten.
Scale your teamFrequently asked questions
Generative models can be difficult to grasp, so let's address common questions.
What is an example of a generative AI model?
GPT-4 is a well-known generative AI model.
What are the two kinds of generative AI models?
Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) are two kinds of generative AI models.
How is generative AI different from AI?
Generative AI focuses on creating new data, while general AI performs tasks based on existing data and patterns.
What are generative algorithms?
These are algorithms that create new data or content, such as images, text, or audio.
What are the techniques used in generative AI?
Techniques used in generative AI: GANs, VAEs, Transformers, and Diffusion Models.
Is ChatGPT a generative model?
ChatGPT is software based on a generative model. It uses a Transformer type of model (specifically, GPT or Generative Pre-trained Transformer) to generate human-like text based on the input it receives.
So, while ChatGPT is an application, the underlying model that powers it is generative.
What is the difference between a generative model and deep learning?
Generative models create new data, while deep learning models often classify or analyze existing data.
What is the difference between OpenAI and generative AI?
OpenAI is an organization, while generative AI refers to AI models that generate new content.
How many types of generative AI are there?
GANs, VAEs, Diffusion Models, and autoregressive models.




