Choosing the Right AI Tech Stack for Your Application

Building AI solutions is easier than ever, with apps taking just days to design and deploy. Thanks to the widespread availability of AI development, there are now plenty of options for functionality, applications, and the technologies that power them. Whether it's choosing a machine learning framework or deciding on deployment options, the modern AI tech stack offers a wide range of tools. The sheer abundance of choices, however, might make decision-making seem a bit overwhelming.
At Flyaps, we have a wealth of experience in building and deploying AI-powered solutions. After working on many projects connected with AI, from CV Compiler to GlossaryTech Chrome extension, we managed to come up with our own approach to choosing the best AI tech stack to address our clients’ needs, which we would like to share with you. We will discuss the three vital aspects of the tech stack for AI solutions and the significant choices that need to be made at each of those phases.
Understanding the AI technology stack
To ensure we’re on the same page, let’s start the ball rolling with a quick definition. The AI tech stack is a stack of technologies, frameworks, and tools that addresses various facets of AI implementation , from data acquisition to the deployment of AI-based solutions.
Picture a ton of different technologies for tons of specific purposes such as managing information, storing data, processing it, employing intelligent algorithms, and so on. AI tech stack is a way to group them into layers for easier perception .
The AI tech stack consists of three layers: model layer, AI infrastructure and AI applications. Let’s explore each layer in detail.

Model layer of the AI software stack
This layer serves as the bedrock of the AI tech stack, where critical algorithms and models for data processing and learning are crafted. A traditional approach to AI models involves developing AI from scratch, but in the last five years, a new type of model has emerged called the foundation model.
Foundation models are a new approach to artificial intelligence that goes beyond old task-specific models. Traditional methods require a large labeled database for each specific task to learn. It takes significant time and resources. Foundation models are trained on large unlabeled datasets, and with minimal fine-tuning, they can be used for a variety of tasks.
GPT-3, BERT, and DALL-E 3 illustrate the potential of foundation models by generating content beyond their specific training, such as essays or pictures from short prompts. It’s also worth highlighting their unique ability to serve as a foundation for multiple applications through self-directed and transfer learning.

At this pivotal stage, breakthrough models are emerging, whether proprietary (such as those developed by OpenAI, Bard, Amazon Titan, Inflection) or open-source.
Proprietary models vs open-source models. Which one should you choose?
Proprietary models, owned by specific companies, come with restricted access and customization, often with licensing costs. In contrast, open-source models, which are collaboratively developed and freely available, allow for extensive customization with no associated fees.

The choice of open-source vs closed-source AI for your AI tech stack depends on factors such as customization needs, budget considerations, and desired user control.
For instance, in the healthcare sector, a pharmaceutical company may develop proprietary predictive models to enhance drug discovery, using internal research data for personalized medicine. On the other hand, a medical research institution might embrace open-source models for their AI tech stack so that they could analyze large-scale genomics data, fostering collaboration and innovation without incurring licensing costs.

AI infrastructure
The AI infrastructure within the AI tech stack is crucial for both model training and inference processes. In training, the system learns from data to improve its performance. On the other hand, inference, also known as prediction, is where the trained model applies its knowledge to new, unseen data.
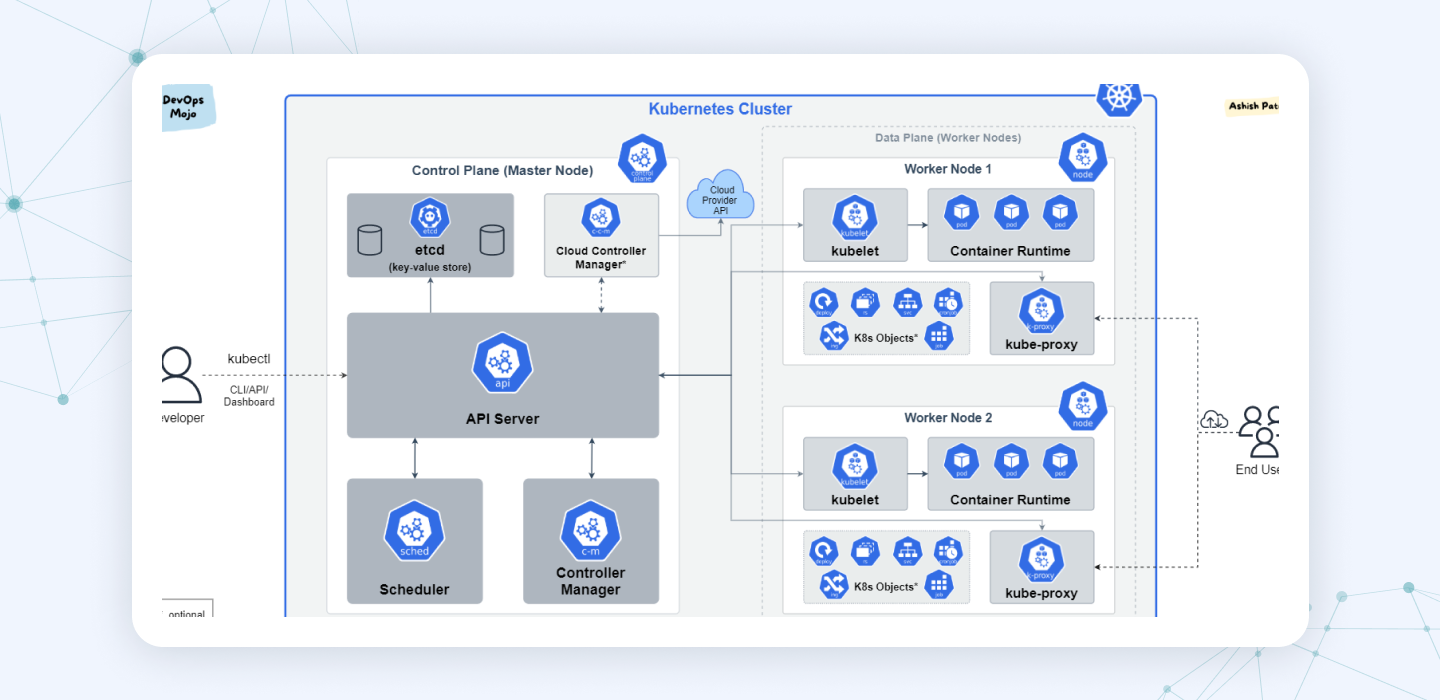
This layer within the AI tech stack is the hub where computational resources such as CPUs, GPUs, and TPUs are assigned and managed. The layer focuses on ensuring scalability, minimizing latency, and incorporating fault tolerance, achieved through the use of orchestration tools like Kubernetes for effective container management.
Four key components constitute this critical layer:
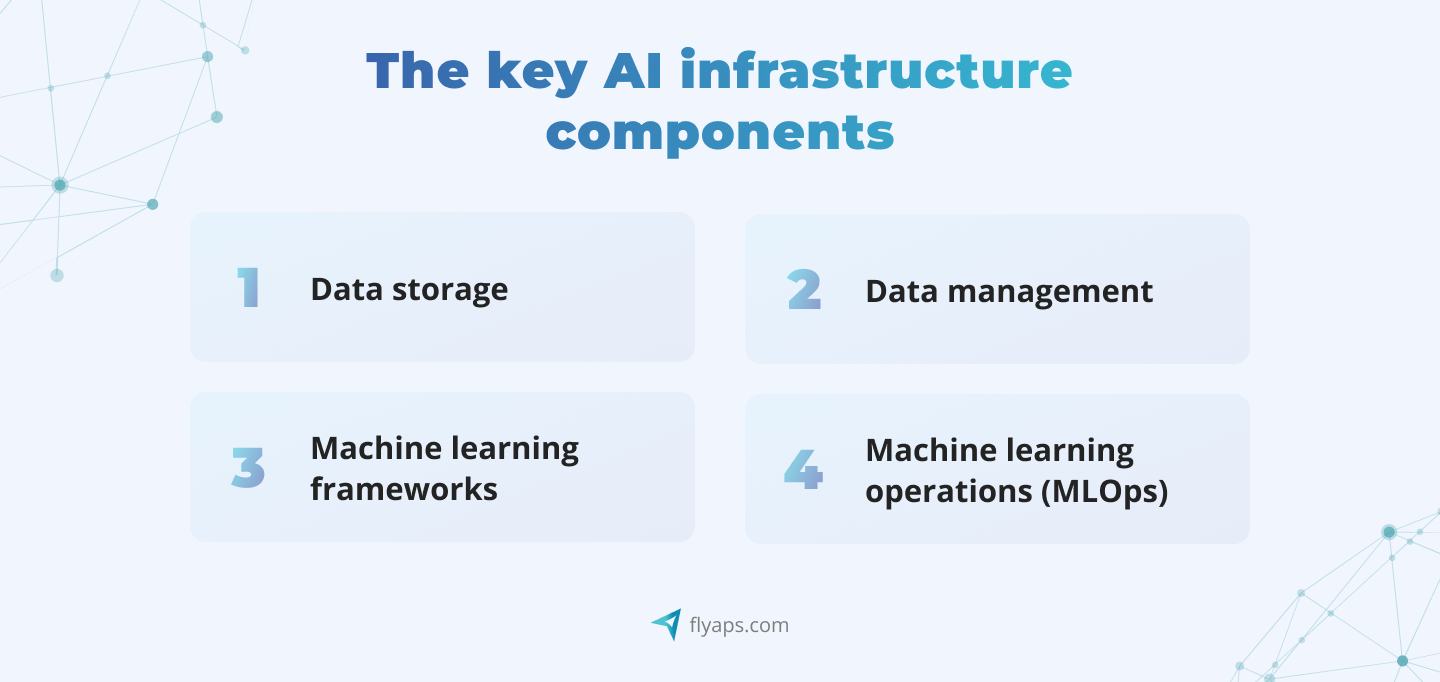
1. Data storage
Suppose, in an e-commerce company, the AI infrastructure manages vast amounts of customer data, including purchase history, preferences, and browsing behavior. The data storage component ensures efficient collection and retention of this information, allowing the company to personalize product recommendations, optimize inventory management, and enhance the overall shopping experience for customers.
2. Data management
Imagine a financial institution that relies on AI for fraud detection. The data management component of the AI infrastructure ensures that transaction data is gathered, stored, and utilized effectively. By implementing robust data management practices, the institution can maintain clarity on the location, ownership, and data accessibility, enabling precise fraud detection algorithms and contributing to secure financial transactions.
3. Machine learning frameworks
Machine learning (ML), a subset of AI, relies on algorithms to identify patterns and make predictions within datasets.
A healthcare organization can use those algorithms for medical image analysis. The machine learning frameworks in the AI infrastructure can provide the necessary AI tools for developers and libraries to design, train, and validate models that can identify patterns in medical images. This enables more accurate diagnoses, faster treatment decisions, and improved patient outcomes.
4. Machine learning operations (MLOps)
MLOps is a set of workflow practices inspired by DevOps and GitOps principles. Its goal is to streamline the entire process of producing, maintaining, and monitoring the machine learning models we've already mentioned.
Suppose, a software development company integrates AI models into its applications for natural language processing. This integration within their AI tech stack allows the company to provide efficient and up-to-date language processing capabilities in its software, enhancing user experience and staying competitive in the market.
As you can see, the role of data in AI infrastructure is paramount. Therefore, when deciding on technology tools for this stage, keep in mind that traditional methods of processing information will not be sufficient for handling massive data sets. What’s more, if your AI-driven solution is to have real-time analytics capabilities, the choice of technology tools for the AI tech stack becomes even more critical.
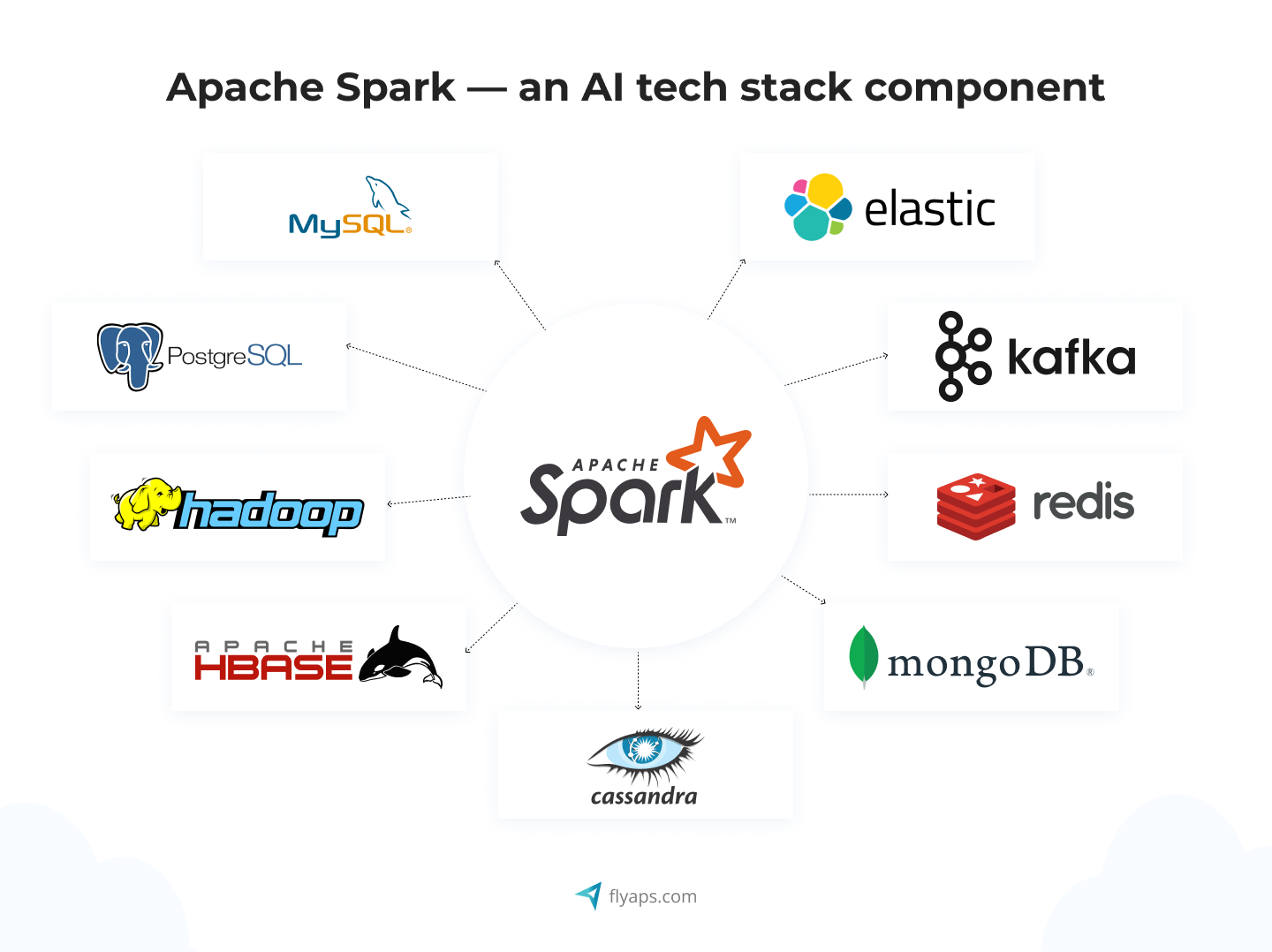
For example, using distributed computing frameworks such as Apache Spark can greatly enhance your system's ability to process and analyze large data sets in parallel, ensuring optimal performance.
Container orchestration platforms, such as Kubernetes, can provide the scalability and flexibility needed to seamlessly manage complex AI workloads.
In addition, integrating event streaming platforms such as Apache Kafka enables a continuous flow of data, ensuring that your real-time analytics remain up-to-date and responsive.

Infrastructure tools, like those we’ve mentioned above, play a key role in transforming abstract AI models and raw data into tangible and practical AI applications. These tools serve as the bridge that translates theoretical concepts into actionable and impactful solutions.
AI applications
The application layer within the AI tech stack serves as the face of user interaction and includes a range of elements from web applications to REST APIs. Its role is critical in managing the flow of data between the user interface and the server. This layer is responsible for basic operations such as collecting user input through graphical user interfaces (GUIs), displaying visualizations on dashboards, and providing data-driven insights through API endpoints.
In the context of AI tech stack, AI applications can take two primary forms: horizontal and vertical.
Horizontal applications
Horizontal applications provide general solutions that can be applied across various industries and business domains. Such solutions are often flexible and adaptable to different contexts, serving a broad user base. Notable examples of horizontal solutions you can choose for your AI tech stack include ChatGPT, DALL-E 3, Alexa, and Google Bard.
Consider the case of an AI-powered customer relationship management (CRM) system. By leveraging the AI infrastructure's data storage and management capabilities, the CRM system efficiently handles a wide range of data sets that include customer interactions, preferences, and purchase history. The inherent flexibility of the infrastructure positions CRM as a general-purpose, adaptable solution that can be used across industries. This adaptability optimizes customer engagement and streamlines sales processes, demonstrating the value of horizontal applications in providing broad and versatile solutions.
Vertical applications
Vertical applications offer tailored functionality and features that cater to the unique requirements of a specific industry or business sector. Examples of such solutions include Darktrace specializing in cybersecurity, and Jasper offering targeted features for the marketing domain.
In the healthcare sector, an example of an AI-powered diagnostic tool tailored for radiology can be provided. The infrastructure's machine learning frameworks empower the development of specialized algorithms for image analysis. The data management component ensures the precise handling of medical imaging datasets. This vertical AI application, designed specifically for healthcare, delivers targeted functionality, aiding radiologists in accurate diagnoses and improving patient care.

Flyaps’ approach to the artificial intelligence technology stack selection
As an AI-focused software development company with over a decade of experience, we at Flyaps have come up with our personal approach to choosing the AI tech stack and AI development platforms for our clients’ projects. Here’s how it looks.
1. Analyzing the project scope and assessing data modality
We begin by analyzing the project scope and assessing the data modality. We tailor the data so the AI system can create new content like images, text, or audio. We consider computational complexity, including neural network layers and data volume, to make informed decisions on hardware and deep learning frameworks to add to your AI tech stack. Our approach ensures the handling of both structured data and unstructured data, allowing us to build effective machine learning models.
Making sure the project can grow and change easily is important to us, so we use cloud infrastructure and cloud services for scalability. We pick techniques that are good at creating things precisely, especially in important areas like drug discovery or self-driving cars. For fast model training and deployment, we focus on optimizing AI applications with real-time evaluation, ensuring speed of execution for real-time applications. We also pay attention to predictive analytics to guide decision-making processes.
2. Balancing budget-friendliness with team-centric technology
Our next move is to align our technology stack with our team's abilities, accelerating development and ensuring an easy learning process. Boosting the power of our chosen computational frameworks is possible by using available GPUs or specialized hardware, which results in better performance. We provide a strong support system that includes detailed documentation, tutorials, and community aid for quick troubleshooting. Balancing budget constraints with the need for a capable technology stack is essential in our decision-making process. This allows us to achieve excellence while staying within our financial means. We prioritize stacks with simple updates after deployment and dependable community or vendor support for an easy and efficient maintenance phase.
3. Strategic scalability measures
As we move to the third stage, we focus on scalability. Our analysis of data volume ensures the effective handling of big data sets through the smart selection of distributed computing frameworks like Apache Spark. We create structures that can handle big loads of requests, either through cloud solutions or microservices. Real-time evaluation guides us to choose efficient models for projects that require instant data processing. We use distributed computing frameworks to enable high-throughput batch operations with precision.
4. Enhancing security and compliance assurance
In our final stage, we prioritize information security and compliance. We ensure data integrity by using strong encryption, role-based access, and data masking to prevent unauthorized manipulation. We also employ model security measures to protect the valuable intellectual assets contained in our AI models. Our plan to protect the infrastructure includes using cybersecurity tools like firewalls and intrusion detection systems to defend against potential threats. We guarantee thorough compliance with industry-specific regulations, like HIPAA and PCI-DSS, to keep sensitive information safe.
Additionally, we use strong protocols to authenticate and authorize users, limiting access to authorized personnel only, and ensuring strong data security.
Let us help you choose - explore our skills and reach out and get expert advice.
Let’s collaborate



