Why We've Used Python for Data Engineering for 12 Years (And Still Do)

Back in 2013, we made a bet on Python. It paid off.
In 2013, we started out as a small team building web apps with Python.
In 2016, we began building machine learning expertise and working with AI development platforms, relying on Python to handle data.
In 2018, our first commercial ML project, CV Compiler, hit the spotlight, being featured on TechCrunch shortly after launch.

At the time, ML/AI were still behind the scenes, and Python was quietly taking ground. Big names like Instagram and Netflix were open-sourcing their Python tools, and it was clear Python wasn’t just for scripting.
So we at Flyaps have been using Python in both small and large projects. Over the years, we became known as a Python-focused company, delivering 30+ Python-based projects since 2013.
Today, one of the main ways we still use it is to work with data, turning raw data into useful information (what data engineering is all about).
In this article, we break down the whys and hows behind using Python in real-world data engineering projects, sharing some of our own cases like CV Compiler.
Why Python for data engineering?
Python is a solid, go-to language for data engineering projects. It’s well-documented, cross-platform, flexible enough to handle data at any scale, and backed by a huge, active community.
Here’s why so many data engineer teams (including ours) keep choosing Python for their data engineering projects:
✔️It’s a must-have skill for data engineers. Python appeared in almost 74% of data engineering job postings in 2024, second only to SQL (79%).
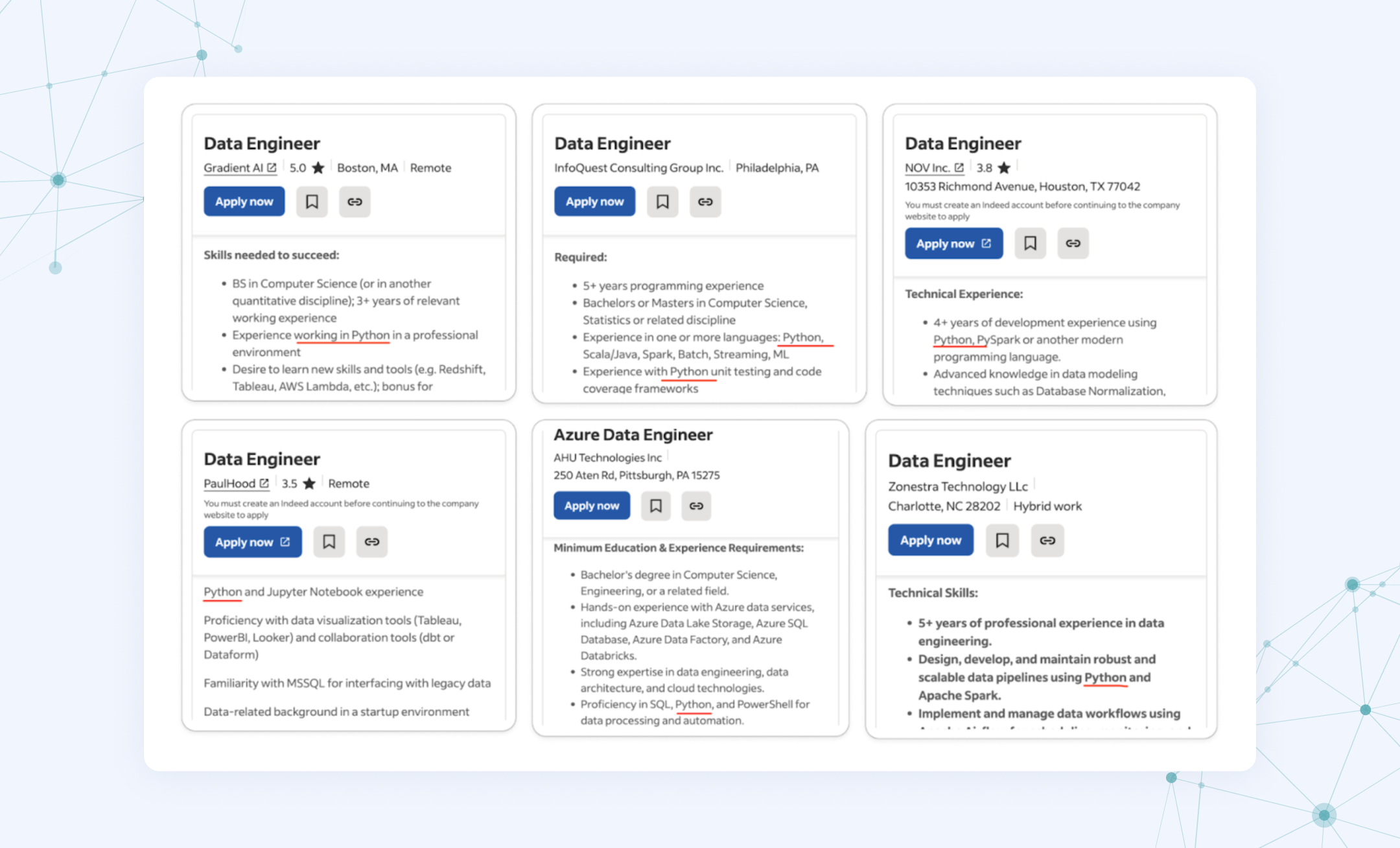
👉For reference, Java, Scala, and R came next, ranked third to fifth. We cover them later in the Python alternatives section.
But while SQL is a go-to for querying databases (and often used alongside Python), Python goes much further. As Paul Crickard, author of Data Engineering with Python, puts it: “Python has become the default language for data science and data engineering.”
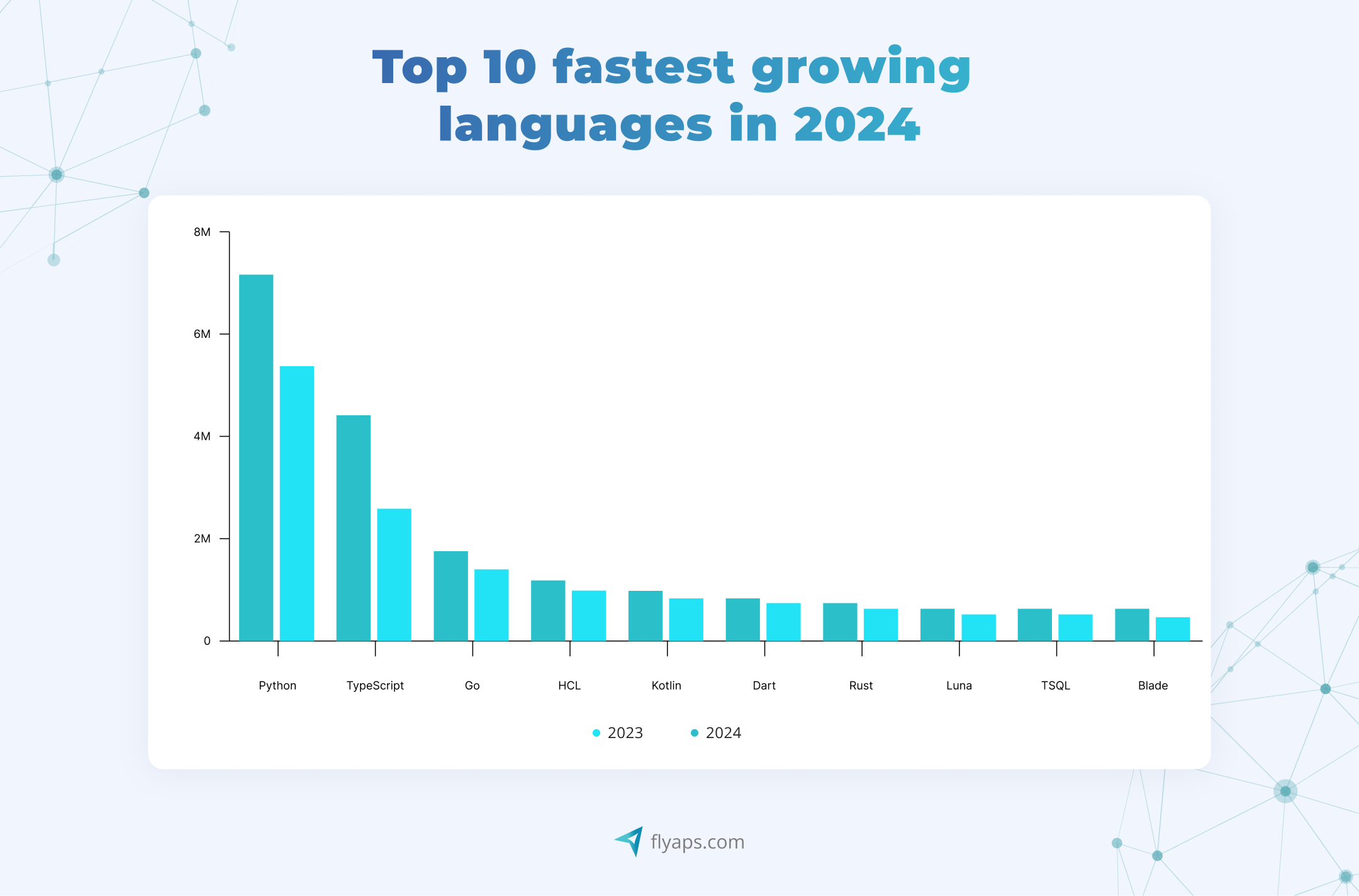
✔️It has a huge community that keeps growing. In 2024, Python became the most used language on GitHub for the first time, mainly in data-heavy fields like machine learning and data science. Its contributors constantly improve tools and build new ones. Just look at how fast the Python Package Index (PyPI) is growing:
| May 2023 | May 2024 | March 2025 |
| 450,000 | 530,000 | 614,000+ |
✔️ It comes with lots of built-in tools for data engineering. Python’s libraries and frameworks save time by giving developers ready-made tools to handle data engineering tasks. Some popular ones include:
- PySpark to process big data
- Pandas to work with tables and structured data
- Apache Airflow to build data engineering pipelines
- OpenCV to analyze and process images and video
- NumPy to handle numbers and complex calculations
✔️ It’s portable. You can run the same Python code across different operating systems (Windows, macOS, Linux) without needing to rewrite it. As long as the system has a Python interpreter installed, your code will work.
✔️ It’s extendable. Python lets you plug in code written in other languages like C or C++ when you need a speed boost. This way, you can keep your main project in Python—easy to read and quick to write—while offloading performance-heavy tasks to faster, lower-level languages. And it’s not just a niche practice. According to the Python Developer Survey, 25% of Python developers also use C/C++, showing how common this kind of hybrid approach really is.
Not bad for a language that’s been around for 30+ years, right?
With its community growing and its use expanding in fields like data science, AI, and automation, we don’t see Python’s popularity cooling off anytime soon and actively use it across our own projects. 👇
Case in point: How Python helped us build one-of-a-kind resume parsing tool
CV Compiler is a machine learning-based resume parser we built at Flyaps for Relocate.me, a platform that helps IT professionals find jobs around the world. The tool scans resumes and gives tech job seekers instant feedback on what they can improve.
To make this work, we needed to engineer a system that processes thousands of resumes in different formats (PDF, Word, you name it), pull out key details, and organize the data in a structured, searchable format.
Here’s how Python helped at each step:
✅ Handling unstructured data efficiently. Resumes come in many different formats, which makes text extraction tricky. We used PyPDF2 and pdfminer to pull text from PDFs, and Pandas to organize the extracted data into a usable format.
✅ Automating data processing. Python scripts processed resumes in batches, while Apache Airflow scheduled these tasks to run automatically, ensuring fast and accurate parsing.
✅ Text analysis and AI integration . The system not only reads resumes but also understands them. Python’s NLP tools identifies job titles, skills, and work experience, categorizing the data for recruiters. Even though Python isn’t the fastest language, its AI and data libraries are built with C, C++, and Fortran behind the scenes, so we still get fast performance with simple, readable code.
✅ API-first approach. CV Compiler had to be easily integrated into other hiring platforms. Using FastAPI, we created an API that lets job boards and hiring tools easily plug CV Compiler into their systems.
✅ Scalable and cloud-friendly. CV Compiler runs as a cloud-native solution. Python’s flexibility allows it to efficiently handle high volumes of data, process resumes in real time without slowing down or crashing, and integrate easily with hiring platforms via an API.
Python’s flexibility made it easy to build a smart AI system that evaluates and improves raw, unstructured resumes. It’s a great fit for any business working with large volumes of messy data.
Core data engineering stages where Python helps
Now, let’s look under the hood and break down where Python really shines in the data engineering process—the key stages that turn raw data into a useful end product for analysts, data scientists, ML engineers, and more.
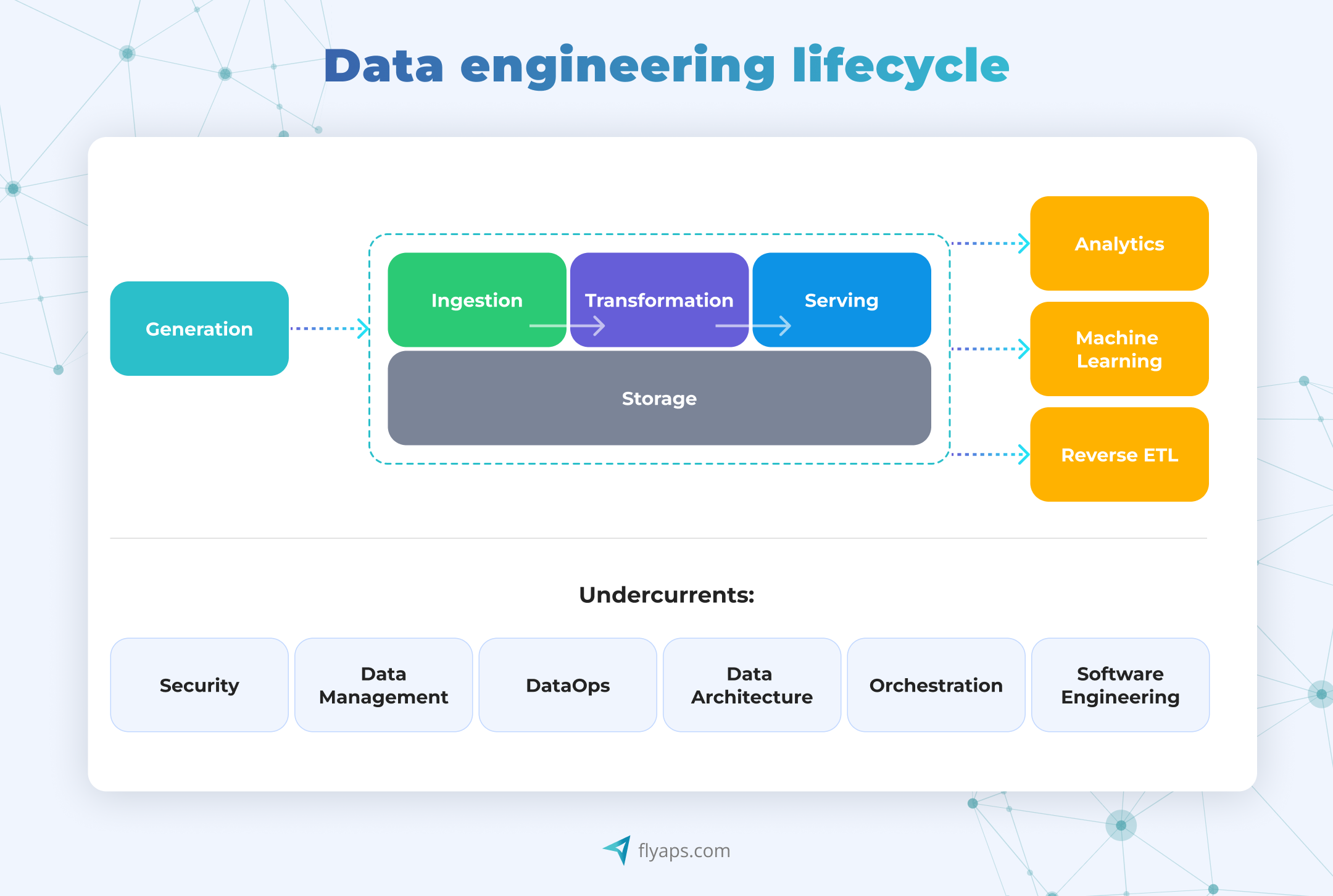
Extracting and loading data (ETL pipelines)
Raw data is often messy. It needs to be cleaned, formatted, and structured before it’s usable. This is where Python’s data manipulation libraries help:
| Database connections | Cloud storage | APIs and files |
| Python connects easily to databases like PostgreSQL, MySQL, MongoDB using SQLAlchemy, psycopg2, and PyMongo. | Libraries like Boto3 (AWS S3), google-cloud-storage (GCP), and Azure SDK handle large-scale data transfers. | Python’s requests library fetches data from APIs, and Pandas reads structured data from CSV, JSON, and Parquet files. |
Transforming and processing data
Raw data is often messy. It needs to be cleaned, formatted, and structured before it’s usable. Here’s how Python saves the day in this case:
| Data wrangling and cleaning | Handling large datasets | Text processing |
| Pandas and Polars help filter, sort, and transform tabular data. | If the data doesn’t fit into memory, Apache Spark (PySpark) and Dask enable distributed processing. | For Natural Language Processing (NLP), libraries like spaCy and NLTK analyze and structure unstructured text. |
Automating data workflows (Scheduling and orchestration)
Businesses rely on automated workflows to keep data moving: updating reports, processing transactions, or feeding AI models. Data engineers make sure these workflows (or "pipelines") run on time and in the right order, like scheduling daily data updates or ensuring tasks run in sequence.
Python helps with:
| Scheduling tasks | Workflow orchestration | Parallel processing |
| Apache Airflow and APScheduler schedule ETL jobs. | Python coordinates multiple processes, ensuring that tasks run in the right order using Airflow DAGs. | Python allows jobs to run in parallel, speeding up execution. |
Ensuring data quality and testing
Businesses need clean, reliable data to make decisions. Data engineers must validate and test pipelines before deploying them. The Python’s role here includes:
| Data quality checks | Automated testing |
| Great Expectations and Cuallee validate data formats, detect missing values, and enforce schema consistency. | pytest and unittest ensure Python scripts work correctly. |
Scaling with cloud and big data tools
As data grows, companies require scalable solutions that can efficiently handle millions of records. Here, Python helps data engineers with:
| Big data processing | Cloud integration | Containerization |
| PySpark processes massive datasets across multiple machines. | Python connects with AWS, GCP, and Azure to process data at scale. | Python apps can be packaged using Docker and deployed efficiently. |
To recap, key data engineering tasks where Python helps are as follows:
| Data engineering stage | What it involves | How Python helps | Key libraties |
| 1. Extracting and loading data | Pulling data from databases, APIs, cloud storage | Fetches, reads, and loads structured/unstructured data | SQLAlchemy, psycopg2, PyMongo, Boto3, requests, Pandas |
| 2. Transforming and processing data | Cleaning and structuring data before analysis | Wrangles, formats, and processes large-scale data | Pandas, Polars, PySpark, Dask, spaCy, NLTK |
| 3. Automating data workflows | Scheduling and managing data pipelines | Automates, schedules, and orchestrates workflows | Apache Airflow, APScheduler |
| 4. Ensuring data quality and testing | Validating and testing pipelines for reliability | Runs quality checks and automated tests | Great Expectations, Cuallee, pytest, unittest |
| 5. Scaling with cloud and big data | Handling massive datasets and cloud integration | Works with cloud storage and big data processing | PySpark, Snowflake Connector, AWS SDKs, Docker |
How we use Python in our data engineering projects: Five real-world applications
We’ve covered how IT specialists can handle key data engineering stages using Python. Next, let’s look at other real-world examples of how we’ve used Python to build AI-supported solutions for our data-heavy clients.
Data ingestion and integration
Business use case: A logistics company needed a system to track cargo loading and optimize space utilization in warehouses. The AI model had to analyze video data from cameras, measure cargo volume, and integrate the data into a warehouse management system.

How Python helps:
- OpenCV extracts cargo dimensions from video footage.
- Pandas and NumPy structure and store the processed data.
- Airflow automates data ingestion and integration into the warehouse system.
Example: Python scripts process real-time warehouse footage, extract cargo volume metrics, and send space optimization recommendations to warehouse operators.
Data cleaning and preprocessing
Business use case: A recruitment platform needed an AI-driven resume parser (yep, that’s the functionality of CV Compiler from before) that could extract skills, job history, and education details from resumes in different formats, including PDFs and Word files. The system had to standardize and clean the extracted data before matching candidates with employers.
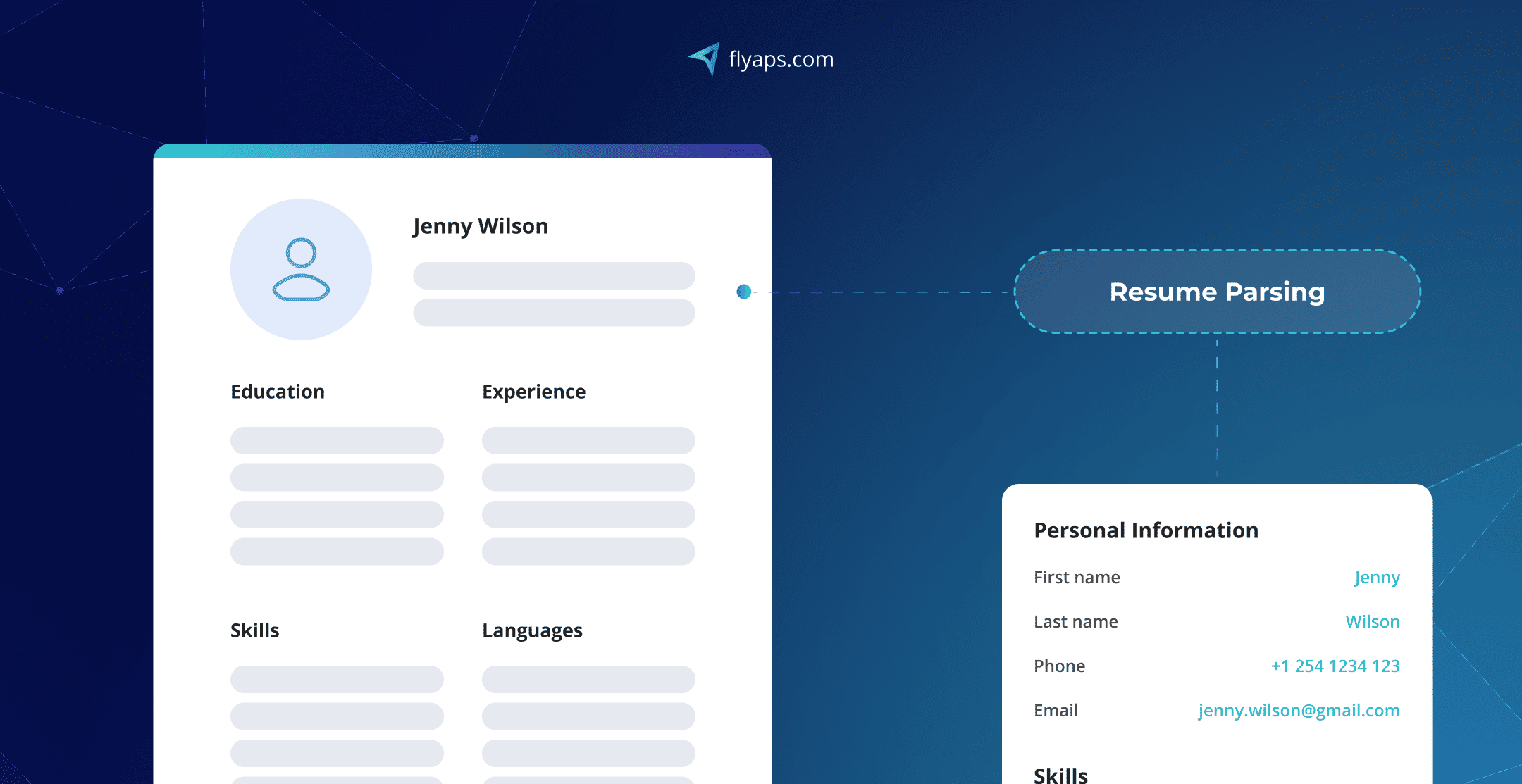
How Python helps:
- PyPDF2 and pdfminer extract text from PDF resumes.
- spaCy and NLTK clean and preprocess unstructured text.
- Pandas structures candidate information into a database-friendly format.
Example: Python scripts automatically clean resume data, removing duplicate entries, normalizing job titles, and structuring candidate profiles, making it easier for recruiters to find the right talent.
Real-time data processing and analysis
Business use case: A retail company wanted a system to track in-store customer movement using camera feeds. The goal was to understand foot traffic, optimize store layouts, and improve marketing strategies.

How Python helps:
- OpenCV and dlib detect and track customers in real-time.
- Pandas organizes time-series foot traffic data.
- SciPy predicts peak shopping hours based on historical trends.
Example: Python processes camera data in real-time to identify high-traffic areas, helping store managers adjust layouts and staffing to improve the shopping experience.
4. Machine learning for predictions and recommendations
Business use case: An online marketplace for used cars needed an AI system to automatically detect car make, model, and estimate pricing based on images uploaded by sellers. The challenge was to process and analyze thousands of car images efficiently.

How Python helps:
- YOLO and OpenCV detect car attributes from images.
- Scikit-learn predicts car prices based on historical sales data.
- Pandas and NumPy store and process structured vehicle specifications.
Example: Python powers the AI model that identifies car models from images and predicts their market value, helping sellers set competitive prices instantly.
5. Automated workflows and AI model deployment
Business use case: An e-commerce company wanted an AI-driven recommendation system to suggest personalized artwork to customers based on their browsing history. The system had to process image data, match similar artworks, and deploy recommendations in real time.
How Python helps:
- TensorFlow and PyTorch train deep learning models for image matching.
- FastAPI builds an API for real-time recommendation delivery.
- AWS Lambda and Python scripts deploy the model at scale.
Example: Python powers an AI system that analyzes user preferences, finds visually similar artworks, and delivers personalized recommendations, increasing customer engagement and sales.
Python alternatives: What else is out there?
Of course, Python is not the only option. Some businesses or projects might need something different, depending on performance needs, industry focus, or personal preference.
Here are some Python alternatives for data engineering and when they might be a better fit:
| Alternative | Best for | Key differences from Python |
| SQL | Querying and managing structured data | Essential for databases. Often used alongside Python, not as a full alternative. |
| Java | Big data processing, complex data pipelines | Runs faster on large-scale systems, widely used in Apache Hadoop and Spark, but harder to learn. |
| Rust | Performance-heavy data applications | Memory-safe and fast, but harder to learn. Good for building database systems. |
| Go (Golang) | High-performance data processing, cloud services | Faster than Python for concurrent processing, used in Kubernetes, Docker, and microservices. |
| Scala | Distributed data processing (Apache Spark) | Faster and more scalable for big data. Works natively with Apache Spark. Often used together with Python for data engineering tasks. |
| R | Statistical analysis, data manipulation, and visualization | Built for stats and visualization. Less versatile for general programming and AI than Python. |
| Julia | High-performance numerical computing; research-heavy, performance-critical projects | Faster than Python for scientific computing but has a smaller ecosystem and requires more setup and compilation work. |
If you're building data pipelines, automation, or working on an AI project, Python is still the top choice. But if you're working on web apps, mobile development, or high-performance systems, another language or a mix might be better.
Some recommendations for your tech stack (and yes, you can mix and match, as do many Python developers):
✅ Use Python if you want an easy-to-learn, AI-friendly language for ETL, automation, cloud workflows, or machine learning. It has a huge library ecosystem and strong support for tools like Pandas, Airflow, and TensorFlow and works well alongside other tools and languages.
✅ Use SQL to interact with relational databases, query data, and manage data stored in structured formats. It’s essential in every data stack and is not a full replacement for Python.
✅ Use Java for large-scale, enterprise data pipelines, especially with Apache Hadoop. It’s fast and stable—great for backend systems—and often runs alongside Python in big data environments.
✅ Use Scala if you're working with Apache Spark or need fast, typed code for big data processing. It runs on the JVM and supports functional programming. Many teams use Scala for the heavy lifting and Python for orchestration or analytics.
✅ Use Go (Golang) for fast, lightweight services or cloud-native tools. It’s great for concurrent tasks and often powers infrastructure around Python-based systems.
✅ Use Rust when building low-level tools or performance-critical systems. You can even use Rust to optimize specific Python components using bindings like PyO3.
✅ Use R for data analysis, statistics, or visualization, especially in research or academic work. It has strong libraries for stats and plotting (like ggplot2 and dplyr). While not as general-purpose as Python, it’s often preferred by statisticians and researchers.
✅ Use Julia for high-performance numerical computing. It’s great for scientific models or Bayesian methods. It’s more niche but can complement Python in research or heavy math use cases.
Solve complex data challenges with pros holding Master's and PhDs in Mathematics. Our experts will put their data engineering skills to work for you.
Hire data engineers


